多线程 - IOS GCD(3)
前言
一、栅栏函数
二、同步函数执行原理
三、死锁的原理
四、同步函数整体流程总结
五、信号量的分析
六、调度组
七、dispatch_source
今天继续来研究GCD相关的技术原理。
一、栅栏函数
1、栅栏函数的使用
研究同步函数之前,先总结一下栅栏函数的使用,栅栏函数也同样会起到同步的作用。
- (void)test {
dispatch_queue_t q = dispatch_queue_create("test", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(q, ^{
sleep(1);
NSLog(@"1");
});
dispatch_barrier_async(q, ^{
});
NSLog(@"2");
dispatch_async(q, ^{
NSLog(@"3");
});
dispatch_async(q, ^{
NSLog(@"4");
});
}
打印顺序为: 2 1 3 4,因为dispatch_barrier_async 会栏住前面的任务,前面的任务执行完毕之后才会走dispatch_barrier_async。
如果使用dispatch_barrier_sync,打印顺序为:1 2 3 4,因为这个函数会阻塞当前调用线程,影响后面的任务执行。
换句话说:dispatch_barrier_async栏的是队列,dispatch_barrier_sync不仅栏队列,还栏线程。
注意:栅栏函数只能控制同一个自定义的并发队列。
2、栅栏函数的应用
- (void)test1 {
dispatch_queue_t concurrentQueue = dispatch_queue_create("test", DISPATCH_QUEUE_CONCURRENT);
for (int i = 0; i < 1000; i++) {
dispatch_async(concurrentQueue, ^{
NSString *imageName = [NSString stringWithFormat:@"%d.jpg", (i % 10)];
NSURL *url = [[NSBundle mainBundle] URLForResource:imageName withExtension:nil];
NSData *data = [NSData dataWithContentsOfURL:url];
UIImage *image = [UIImage imageWithData:data];
[self.mArray addObject:image];
});
}
}
以上代码运行会崩溃: malloc: *** error for object 0x600003a946f0: pointer being freed was not allocated
崩溃的原因是:image在多线程执行的过程中,会不断的进行retain和release,当某一条线程执行mArray添加操作后,image可能再次被release,造成内存混乱,所以崩溃了。
此时可以通过加锁解决:
@synchronized (self) {
[self.mArray addObject:image];
}
同样也可以使用栅栏函数来解决:
dispatch_barrier_async(concurrentQueue, ^{
[self.mArray addObject:image];
});
二、同步函数执行原理
直接看源码:
//同步函数调用
void
dispatch_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
//基本会走这里
/*
1.dq 队列
2.work block任务
3._dispatch_Block_invoke(work) block内部的invoke函数指针
4.dc_flags 标识
*/
_dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
进入_dispatch_sync_f
/*
1.dq 队列
2.ctxt block任务
3._dispatch_Block_invoke(work) = func block内部的invoke函数指针
4.dc_flags 标识
*/
static void
_dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func,
uintptr_t dc_flags)
{
_dispatch_sync_f_inline(dq, ctxt, func, dc_flags);
}
进入_dispatch_sync_f_inline
//内联函数
/*
1.dq 队列
2.ctxt block任务
3._dispatch_Block_invoke(work) = func block内部的invoke函数指针
4.dc_flags 标识
*/
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
//判断队列是否是串行队列
//dq_width = 1 就是串行队列
if (likely(dq->dq_width == 1)) {
return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags);
}
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
// Global concurrent queues and queues bound to non-dispatch threads
// always fall into the slow case, see DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE
if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) {
return _dispatch_sync_f_slow(dl, ctxt, func, 0, dl, dc_flags);
}
if (unlikely(dq->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func, dc_flags);
}
_dispatch_introspection_sync_begin(dl);
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));
}
当“dq->dq_width == 1”时是串行队列,先分析串行队列的情况。此时会进入_dispatch_barrier_sync_f函数,这个函数也是同步栅栏函数的底层函数:
void
dispatch_barrier_sync(dispatch_queue_t dq, dispatch_block_t work)
{
uintptr_t dc_flags = DC_FLAG_BARRIER | DC_FLAG_BLOCK;
if (unlikely(_dispatch_block_has_private_data(work))) {
return _dispatch_sync_block_with_privdata(dq, work, dc_flags);
}
_dispatch_barrier_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags);
}
此时可以得出结论:串行队列+同步函数 = 串行队列+同步栅栏函数。
继续进入_dispatch_barrier_sync_f
static void
_dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
_dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags);
}
进入_dispatch_barrier_sync_f_inline
/*
1.dq 队列
2.ctxt block任务
3._dispatch_Block_invoke(work) = func block内部的invoke函数指针
4.dc_flags 标识
*/
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
//获取线程ID -- mach pthread --
dispatch_tid tid = _dispatch_tid_self();
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) {
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,
DC_FLAG_BARRIER | dc_flags);
}
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
//准备开始
_dispatch_introspection_sync_begin(dl);
//执行
_dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func
DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop(
dq, ctxt, func, dc_flags | DC_FLAG_BARRIER)));
}
先看_dispatch_introspection_sync_begin
static inline void
_dispatch_introspection_sync_begin(dispatch_queue_class_t dq)
{
if (!_dispatch_introspection.debug_queue_inversions) return;
_dispatch_introspection_order_record(dq._dq);
}
在_dispatch_introspection_sync_begin 函数中会执行 _dispatch_introspection_order_record。_dispatch_introspection_order_record 函数大致就是在同步任务调用之前,做的一系列条件准备和记录,不做深入分析了。
重点来到_dispatch_lane_barrier_sync_invoke_and_complete函数:
static void
_dispatch_lane_barrier_sync_invoke_and_complete(dispatch_lane_t dq,
void *ctxt, dispatch_function_t func DISPATCH_TRACE_ARG(void *dc))
{
//任务执行
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
_dispatch_trace_item_complete(dc);
if (unlikely(dq->dq_items_tail || dq->dq_width > 1)) {
return _dispatch_lane_barrier_complete(dq, 0, 0);
}
//任务完成之后进行解锁
const uint64_t fail_unlock_mask = DISPATCH_QUEUE_SUSPEND_BITS_MASK |
DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_DIRTY |
DISPATCH_QUEUE_RECEIVED_OVERRIDE |
DISPATCH_QUEUE_RECEIVED_SYNC_WAIT;
uint64_t old_state, new_state;
dispatch_wakeup_flags_t flags = 0;
// similar to _dispatch_queue_drain_try_unlock
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = old_state - DISPATCH_QUEUE_SERIAL_DRAIN_OWNED;
new_state &= ~DISPATCH_QUEUE_DRAIN_UNLOCK_MASK;
new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK;
if (unlikely(old_state & fail_unlock_mask)) {
os_atomic_rmw_loop_give_up({
return _dispatch_lane_barrier_complete(dq, 0, flags);
});
}
});
if (_dq_state_is_base_wlh(old_state)) {
_dispatch_event_loop_assert_not_owned((dispatch_wlh_t)dq);
}
}
static inline void
_dispatch_sync_function_invoke_inline(dispatch_queue_class_t dq, void *ctxt,
dispatch_function_t func)
{
dispatch_thread_frame_s dtf;
_dispatch_thread_frame_push(&dtf, dq);
_dispatch_client_callout(ctxt, func);
_dispatch_perfmon_workitem_inc();
_dispatch_thread_frame_pop(&dtf);
}
此函数注意做了2件事情:(1)任务执行(2)任务完成后,改变底层状态,解锁。
回到_dispatch_sync_f_inline函数,看下并发队列的执行
static inline void
_dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
//.... 省略
_dispatch_introspection_sync_begin(dl);
_dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(
_dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags)));
}
static void
_dispatch_sync_invoke_and_complete(dispatch_lane_t dq, void *ctxt,
dispatch_function_t func DISPATCH_TRACE_ARG(void *dc))
{
_dispatch_sync_function_invoke_inline(dq, ctxt, func);
_dispatch_trace_item_complete(dc);
_dispatch_lane_non_barrier_complete(dq, 0);
}
会发现,和串行队列的逻辑大致是一样的。
这就是同步函数的整体执行流程了。
三、死锁的原理
之前的死锁案例,通常发生在“同步函数”中,通过以上同步函数执行流程分析,继续来研究一下死锁产生的原因。
首先我们打印一下死锁的堆栈:
dispatch_queue_t cq = dispatch_queue_create("xxx", NULL);
dispatch_sync(cq, ^{
NSLog(@"%@===",[NSThread currentThread]);
dispatch_sync(cq, ^{
NSLog(@"%@===",[NSThread currentThread]);
});
});
堆栈如下:

可以看到,执行了_dispatch_sync_f_slow函数。
我们回到_dispatch_barrier_sync_f_inline函数中:
static inline void
_dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt,
dispatch_function_t func, uintptr_t dc_flags)
{
//获取线程ID -- mach pthread --
dispatch_tid tid = _dispatch_tid_self();
if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) {
DISPATCH_CLIENT_CRASH(0, "Queue type doesn't support dispatch_sync");
}
dispatch_lane_t dl = upcast(dq)._dl;
//判断线程状态,需不需要等待,是否回收
if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) { //栅栏函数也会死锁
return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl,
DC_FLAG_BARRIER | dc_flags);
}
//验证target是否存在,如果存在,加入栅栏函数的递归查找
if (unlikely(dl->do_targetq->do_targetq)) {
return _dispatch_sync_recurse(dl, ctxt, func,
DC_FLAG_BARRIER | dc_flags);
}
//...省略
}
当我们获取到当前线程id时,会通过_dispatch_queue_try_acquire_barrier_sync函数来判断线程状态,是否存在等待或者挂起状态以及是否回收。
static inline bool
_dispatch_queue_try_acquire_barrier_sync(dispatch_queue_class_t dq, uint32_t tid)
{
return _dispatch_queue_try_acquire_barrier_sync_and_suspend(dq._dl, tid, 0);
}
然后如果产生了死锁,就会来到_dispatch_sync_f_slow:
static void
_dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt,
dispatch_function_t func, uintptr_t top_dc_flags,
dispatch_queue_class_t dqu, uintptr_t dc_flags)
{
dispatch_queue_t top_dq = top_dqu._dq;
dispatch_queue_t dq = dqu._dq;
if (unlikely(!dq->do_targetq)) {
return _dispatch_sync_function_invoke(dq, ctxt, func);
}
//任务封装
pthread_priority_t pp = _dispatch_get_priority();
struct dispatch_sync_context_s dsc = {
.dc_flags = DC_FLAG_SYNC_WAITER | dc_flags,
.dc_func = _dispatch_async_and_wait_invoke,
.dc_ctxt = &dsc,
.dc_other = top_dq,
.dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG,
.dc_voucher = _voucher_get(),
.dsc_func = func,
.dsc_ctxt = ctxt,
.dsc_waiter = _dispatch_tid_self(),
};
//将任务加入队列
_dispatch_trace_item_push(top_dq, &dsc);
//死锁最终进入
__DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq);
if (dsc.dsc_func == NULL) {
// dsc_func being cleared means that the block ran on another thread ie.
// case (2) as listed in _dispatch_async_and_wait_f_slow.
dispatch_queue_t stop_dq = dsc.dc_other;
return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags);
}
_dispatch_introspection_sync_begin(top_dq);
_dispatch_trace_item_pop(top_dq, &dsc);
_dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func,top_dc_flags
DISPATCH_TRACE_ARG(&dsc));
}
死锁会进入__DISPATCH_WAIT_FOR_QUEUE__
static void
__DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq)
{
uint64_t dq_state = _dispatch_wait_prepare(dq);
if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) {
DISPATCH_CLIENT_CRASH((uintptr_t)dq_state,
"dispatch_sync called on queue "
"already owned by current thread");
}
//...省略
}
这里crash的原因就是:dispatch_sync在当前线程已经拥有的队列上调用,你来晚一步。
其中dsc_waiter是由前面_dispatch_sync_f_slow方法传进来的:.dsc_waiter = _dispatch_tid_self(),也就是线程id。
static inline bool
_dq_state_drain_locked_by(uint64_t dq_state, dispatch_tid tid)
{
return _dispatch_lock_is_locked_by((dispatch_lock)dq_state, tid);
}
static inline bool
_dispatch_lock_is_locked_by(dispatch_lock lock_value, dispatch_tid tid)
{
// equivalent to _dispatch_lock_owner(lock_value) == tid
return ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0;
}
其中:DLOCK_OWNER_MASK
#define DLOCK_OWNER_MASK ((dispatch_lock)0xfffffffc)
分析:((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0
lock_value 是队列的状态,tid是当前线程id。
当一个数 &(与上) DLOCK_OWNER_MASK == 0 那这个数一定是0, 所以(lock_value ^ tid) 为0
(lock_value ^(异或) tid) 为0 也就说明 lock_value 和 tid 相等,也就是当前的队列状态和当前的线程要有关联,并是不是意思上的相等。(可以理解为同一个线程下同一个队列)
当 ((lock_value ^ tid) & DLOCK_OWNER_MASK) == 0 成立时,if条件为真就会促发崩溃 。
总结: 当前队列里面要等待的线程 id和我调用的是一样,我已经处于等待状态,你现在有新的任务过来,又需要使用我去执行,这样产生了矛盾,进入相互等待状态,进而产生死锁。这就是串行队列执行同步任务产生死锁的原因!
换句话说:在当前线程中同步(sync)的向同一个串行队列添加任务时就会死锁崩溃。
四、同步函数整体流程总结
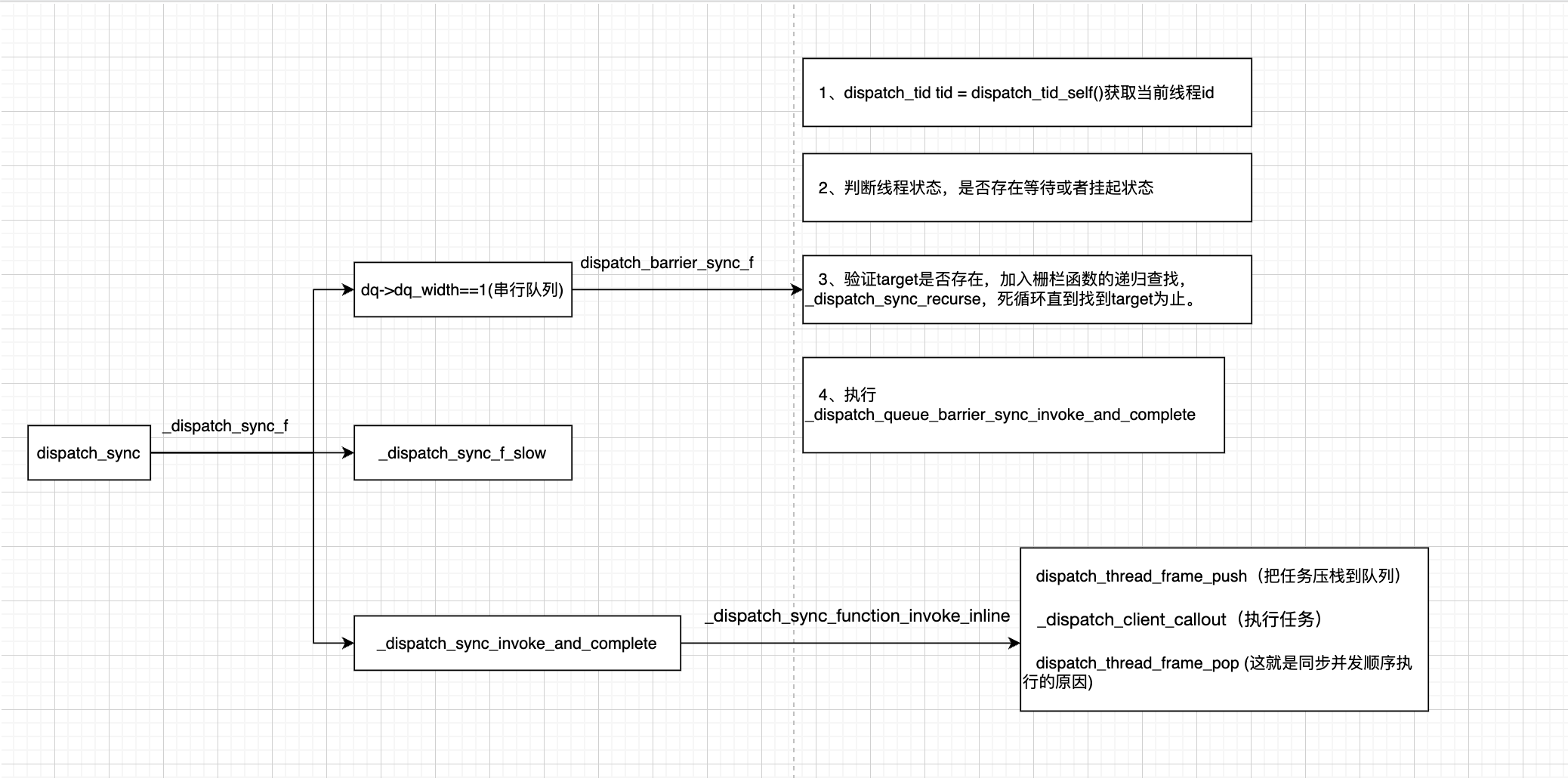
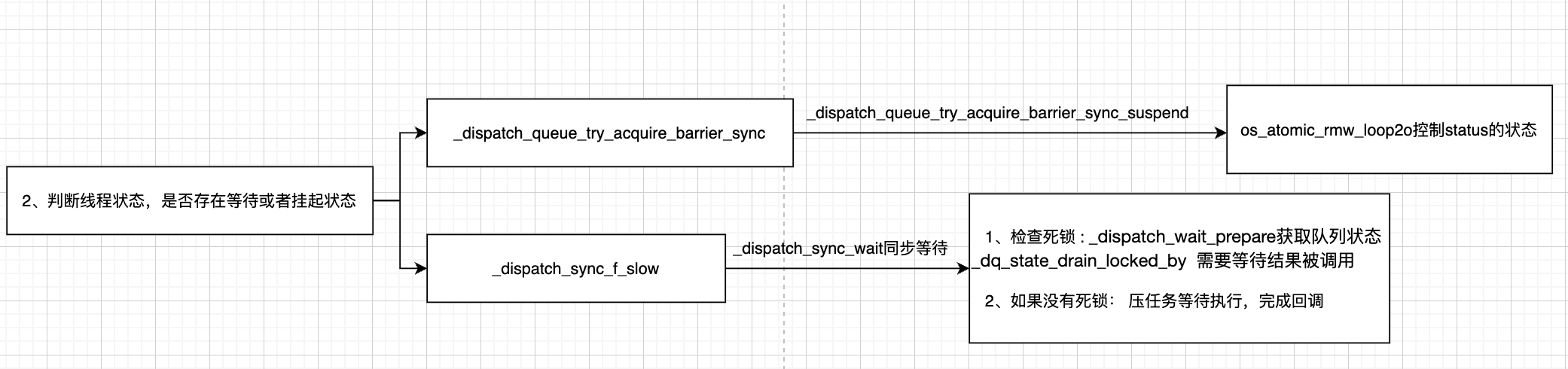
五、信号量的分析
1、信号量的使用
在操作系统中,进程之间,PV操作也是结合信号量来操作的。
那么在GCD中,信号量主要是用来控制GCD线程最大并发数。
关于信号量的一些定义如下:
dispatch_semaphore_create 创建信号量
dispatch_semaphore_wait 信号量等待
dispatch_semaphore_signal 信号量释放
demo如下:
- (void)test {
dispatch_semaphore_t sem = dispatch_semaphore_create(1);
//任务1
dispatch_async(dispatch_get_global_queue(0, 0), ^{
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
NSLog(@"执行任务1");
sleep(1);
NSLog(@"任务1完成");
dispatch_semaphore_signal(sem);
});
//任务2
dispatch_async(dispatch_get_global_queue(0, 0), ^{
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
NSLog(@"执行任务2");
sleep(1);
NSLog(@"任务2完成");
dispatch_semaphore_signal(sem);
});
}
2、信号量的底层分析
首先是创建信号量 dispatch_semaphore_create
dispatch_semaphore_t
dispatch_semaphore_create(intptr_t value)
{
dispatch_semaphore_t dsema;
//初始化值不能小于0
if (value < 0) {
return DISPATCH_BAD_INPUT;
}
//创建信号量对象
dsema = _dispatch_object_alloc(DISPATCH_VTABLE(semaphore),
sizeof(struct dispatch_semaphore_s));
dsema->do_next = DISPATCH_OBJECT_LISTLESS;
dsema->do_targetq = _dispatch_get_default_queue(false);
//赋初始值
dsema->dsema_value = value;
_dispatch_sema4_init(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
dsema->dsema_orig = value;
return dsema;
}
注意:创建信号量时,初始值不能小于0。
继续来到dispatch_semaphore_signal:
intptr_t
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);
}
dispatch_semaphore_signal中应该会对dsema_value进行++的操作。
分析宏定义:
//p = dsema , f = dsema_value m = release
#define os_atomic_inc2o(p, f, m) \
os_atomic_add2o(p, f, 1, m)
os_atomic_add2o对应的宏:
//p = dsema , f = dsema_value v=1 m = release
#define os_atomic_add2o(p, f, v, m) \
os_atomic_add(&(p)->f, (v), m)
os_atomic_add对应的宏:
//p = dsema->dsema_value v=1 m = release
#define os_atomic_add(p, v, m) \
_os_atomic_c11_op((p), (v), m, add, +)
_os_atomic_c11_op对应的宏:
#define _os_atomic_c11_op(p, v, m, o, op) \
({ _os_atomic_basetypeof(p) _v = (v), _r = \
atomic_fetch_##o##_explicit(_os_atomic_c11_atomic(p), _v, \
memory_order_##m); (__typeof__(_r))(_r op _v); })
到了这一步之后,atomic_fetch_##o##_explicit 中的o 也就是 add,那么函数转换为:
atomic_fetch_add_explicit,此函数也就是原子性的加操作。 也就验证了dispatch_semaphore_signal是对值进行++。
同理dispatch_semaphore_wait对应的--函数就是atomic_fetch_sub_explicit。
intptr_t
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {
return 0;
}
//长等待
return _dispatch_semaphore_wait_slow(dsema, timeout);
}
至于为什么++ /-- 搞的这么复杂,应该是为了多个c++或者底层接口的适配性。
六、调度组
1、调度组的使用总结
关于调度组的一些定义如下:
dispatch_group_create 创建组
dispatch_group_async 进组任务
dispatch_group_notify 进组任务执行完毕通知
dispatch_group_wait 进组任务执行等待阻塞
dispatch_group_enter 进组
dispatch_group_leave 出组
demo如下:
- (void)test {
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t concurrentQ = dispatch_queue_create("xxx", DISPATCH_QUEUE_CONCURRENT);
//进组
dispatch_group_enter(group);
dispatch_async(concurrentQ, ^{
sleep(1);
NSLog(@"1");
//出组
dispatch_group_leave(group);
});
dispatch_group_async(group, concurrentQ, ^{
NSLog(@"2");
});
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
NSLog(@"finish");
});
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
NSLog(@"继续执行");
}
打印顺序为:2 1 继续执行 finish
以上就是调度组的用法,举一个在平时开发中使用调度组的例子:
1、比如一个页面展示,需要依赖多个网络请求并且要在所有请求成功之后再渲染页面的情况。
2、下载2张图片,然后合成一张图片的场景等。
2、调度组的底层分析
带着2个核心问题来研究调度组的源码:
(1)dispatch_group_enter和dispatch_group_leave为什么要成对出现
(2)dispatch_group_async 为什么可以代替dispatch_group_enter和dispatch_group_leave。
首先来到dispatch_group_create函数
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // <rdar://22318411>
}
return dg;
}
底层就是简单的创建了一个dispatch_group_t对象,其中dg_bits默认为0。
继续看dispatch_group_enter:
#define DISPATCH_GROUP_VALUE_INTERVAL 0x0000000000000004ULL
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
// 该值在 32 位宽的原子上递减,因此 0 -> -1 转换的进位 // 不会传播到高 32 位。
//dg->dg_bits - 4
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
//以下情况很少发生,不做分析
if (unlikely(old_value == 0)) {
_dispatch_retain(dg); // <rdar://problem/22318411>
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
dispatch_group_enter函数中就是对当前的dg_bits进行减4操作,和信号量类似。
再看dispatch_group_leave:
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
// 该值在 64 位宽的原子上递增,以便 // -1 -> 0 转换的进位以原子方式递增生成。
//对dg->dg_state 加4
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);
}
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
注意dg_state是uint64_t类型, (uint64_t)-1 == (uint64_t)(unsigned)-1 //0x00000000ffffffff (uint64_t)-1 == (uint64_t)(int64_t)-1 //0xffffffffffffffff
里面的运算就不具体分析了,重点分析流程:
(1)当多次调用dispatch_group_leave时,会造成old_value==0,造成crash。
(2)当old_value == DISPATCH_GROUP_VALUE_1时,就会进入循环,并且会走_dispatch_group_wake来通知。
再看dispatch_group_notify函数:
void
dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dsn = _dispatch_continuation_alloc();
_dispatch_continuation_init(dsn, dq, db, 0, DC_FLAG_CONSUME);
_dispatch_group_notify(dg, dq, dsn);
}
可以看到类似异步函数调用时,将任务包装起来,并保存。
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
uint64_t old_state, new_state;
dispatch_continuation_t prev;
dsn->dc_data = dq;
_dispatch_retain(dq);
prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);
if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);
os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);
if (os_mpsc_push_was_empty(prev)) {
os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {
new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;
if ((uint32_t)old_state == 0) {
os_atomic_rmw_loop_give_up({
return _dispatch_group_wake(dg, new_state, false);
});
}
});
}
}
然后_dispatch_group_notify函数中,当old_state==0时,也会返回并执行_dispatch_group_wake。
比如我们不加任何的enter和leave,直接调用dispatch_group_notify,也会直接执行回调。
- (void)test3 {
dispatch_group_t group = dispatch_group_create();
dispatch_group_notify(group, dispatch_get_main_queue(), ^{
NSLog(@"finish");
});
}
//打印:finish
最后来到核心函数_dispatch_group_wake
static void
_dispatch_group_wake(dispatch_group_t dg, uint64_t dg_state, bool needs_release)
{
uint16_t refs = needs_release ? 1 : 0; // <rdar://problem/22318411>
if (dg_state & DISPATCH_GROUP_HAS_NOTIFS) {
dispatch_continuation_t dc, next_dc, tail;
// Snapshot before anything is notified/woken <rdar://problem/8554546>
dc = os_mpsc_capture_snapshot(os_mpsc(dg, dg_notify), &tail);
do {
dispatch_queue_t dsn_queue = (dispatch_queue_t)dc->dc_data;
next_dc = os_mpsc_pop_snapshot_head(dc, tail, do_next);
_dispatch_continuation_async(dsn_queue, dc,
_dispatch_qos_from_pp(dc->dc_priority), dc->dc_flags);
_dispatch_release(dsn_queue);
} while ((dc = next_dc));
refs++;
}
if (dg_state & DISPATCH_GROUP_HAS_WAITERS) {
_dispatch_wake_by_address(&dg->dg_gen);
}
if (refs) _dispatch_release_n(dg, refs);
}
此函数和异步函数调用流程非常的相似,最终会执行上层任务。
3.dispatch_group_async
dispatch_group_async为什么等价于dispatch_group_enter & dispatch_group_leave
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);
_dispatch_continuation_group_async(dg, dq, dc, qos);
}
继续来到_dispatch_continuation_group_async函数:
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc, dispatch_qos_t qos)
{
dispatch_group_enter(dg);
dc->dc_data = dg;
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
可以看到调用了dispatch_group_enter函数,之后就直接进入异步函数调用流程了,并没有看到dispatch_group_leave。
那么dispatch_group_leave一定是在执行完任务之后去调用的,通过以往的分析和符号断点调试,回调任务时,底层一定是调用了_dispatch_client_callout函数,所以全局搜索_dispatch_client_callout。
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data;
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) {
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);
_dispatch_trace_item_complete(dc);
dispatch_group_leave((dispatch_group_t)dou);
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
}
发现此时如果是DISPATCH_GROUP_TYPE类型时,会执行dispatch_group_leave,这就是为什么dispatch_group_async封装了dispatch_group_enter & dispatch_group_leave的原因!
七、dispatch_source
dispatch_source是基础数据类型,用于协调特定底层系统事件的处理。
1、关于dispatch_source的一些定义如下:
dispatch_source_create 创建源
dispatch_source_set_event_handler 设置源事件回调
dispatch_source_merge_data 源事件设置数据
dispatch_source_get_data 获取源事件数据
dispatch_resume 继续
dispatch_suspend 挂起
dispatch_source_cancel 取消源事件
2、倒计时
- (void)test1 {
__block int timeOut = 60;
dispatch_source_t source = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, dispatch_get_global_queue(0, 0));
dispatch_source_set_timer(source, dispatch_walltime(NULL, 0), 1.0*NSEC_PER_SEC, 0);
dispatch_source_set_event_handler(source, ^{
NSLog(@"%i",timeOut);
timeOut --;
if (timeOut <= 0) {
dispatch_source_cancel(source);
}
});
dispatch_resume(source);
}
注意:
(1)当调用了dispatch_suspend之后,再调用dispatch_source_cancel就会崩溃。
dispatch_suspend 只是把 Timer 暂时挂起,它和 dispatch_resume 是一个平衡调用,两者分别会减少和增加 dispatch 对象的挂起计数。
当这个计数大于 0 的时候,Timer 就会执行。在挂起期间,产生的事件会积累起来,等到 resume 的时候会融合为一个事件发送。
因为dispatch_suspend 和 dispatch_resume 应该是成对出现的,两者分别会减少和增加 dispatch 对象的挂起计数,但是没有 API 获取当前是挂起还是执行状态,所以需要自己记录,否则会出现Crash。
(2)循环引用问题
因为dispatch_source_set_event_handler回调是个block,在添加到source的链表上时会执行copy并被source强引用,block内如果持有self,self也持有source,此时会形成循环引用。需要用weak+strong来解决。
(3)source在suspend状态下,如果直接设置source = nil或者重新创建source都会造成crash。
正确的方式是在resume状态下调用dispatch_source_cancel(source)释放当前的source。
3、Dispatch Source的种类:
####(1)DISPATCH_SOURCE_TYPE_DATA_ADD 变量增加
例如设置进度:
- (void)test2 {
self.dataSource = dispatch_source_create(DISPATCH_SOURCE_TYPE_DATA_ADD, 0, 0, dispatch_get_global_queue(0, 0));
__weak typeof(self)weakself = self;
dispatch_source_set_event_handler(self.dataSource, ^{
NSLog(@"%@",[NSThread currentThread]);
NSInteger value = dispatch_source_get_data(weakself.dataSource);
NSLog(@"%li",value);
});
dispatch_resume(self.dataSource);
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event {
//累加
self.totalComplete ++;
dispatch_source_merge_data(self.dataSource, self.totalComplete);
}
####(2)DISPATCH_SOURCE_TYPE_DATA_OR 变量 OR
####(3)DISPATCH_SOURCE_TYPE_MACH_SEND MACH端口发送
####(4)DISPATCH_SOURCE_TYPE_MACH_RECV MACH端口接收
####(5)DISPATCH_SOURCE_TYPE_MEMORYPRESSURE 内存压力 (注:iOS8后可用)
####(6)DISPATCH_SOURCE_TYPE_PROC 检测到与进程相关的事件
####(7)DISPATCH_SOURCE_TYPE_READ 可读取文件映像
####(8)DISPATCH_SOURCE_TYPE_SIGNAL 接收信号
####(9)DISPATCH_SOURCE_TYPE_TIMER 定时器
####(10)DISPATCH_SOURCE_TYPE_VNODE 文件系统有变更
####(11)DISPATCH_SOURCE_TYPE_WRITE 可写入文件映像
4、性能
dispatch_source可以替代异步回调函数,来处理系统相关的事件。
使用 Dispatch Source 而不使用 dispatch_async 的唯一原因就是利用联结的优势。
联结的大致流程为:在任一线程上调用它的一个函数dispatch_source_merge_data后,会执行Dispatch Source事先定义好的句柄(可以把句柄简单理解为一个block),这个过程叫 Custom event(用户事件)。是 dispatch source 支持处理的一种事件。
简单来说:这种事件是由你调用 dispatch_source_merge_data 函数来向自己发出的信号。
其特点就是:
(1)CPU负荷非常小,尽量不占用资源
(2)联结的优势