IOS底层 - LLVM初探
前言
一、编辑器、编译器以及IDE的区别
二、LLVM概述
三、LLVM的设计
四、编译流程
之前分析学习了很多IOS运行时的底层原理,比如Runtime、RunLoop等。今天总结学习一些编译器相关的知识点。
一、编辑器、编译器以及IDE的区别
日常开发中,可能混淆编辑器、编译器以及IDE的概念。但它们是不同概念的:
1、编辑器
编辑器是一个软件程序,常见的有文本编译器、网页编译器、源程序编译器、图像编译器等。
这里主要讲的是代码编译器,比如:NodePad++、VIM等。
2、编译器
编译器简单的来说就是:将你所编辑的源代码编译成机器所能理解的语言(通过编译器将高级语言的代码转化成CPU能看得懂的01组合)。
3、IDE
IDE就是集成开发环境(Integrated Development Enironment),它一般包括代码编辑器、编译器、调试器和图形用户界面工具。集成了代码编写功能,分析功能、编译功能、调试功能等一体化的开发软件服务套。
比如Xcode、Eclipse、Idea等。
二、LLVM概述
了解了编辑器、编译器以及IDE的区别之后,今天具体分析苹果使用的编译器 - LLVM。
1、LLVM是什么
LLVM是架构编译器(compiler)的框架系统(llvm 是一个编译器,也是一个编译器架构),以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
2、LLVM的历史
LLVM计划启动于2000年,最初由美国UIUC大学的Chris Lattner博士主持开展。
2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用。LLVM也相当于成了Apple的官方支持的编译器。Apple也是LLVM计划的主要资助者。
目前LLVM已经被苹果IOS开发工具、Xilinx Vicado、Facebook、Google等各大公司采用。
3、解释形语言和编译形语言
(1)解释形语言,比如python
我们创建一个python文件,demo.py
print("hello\n")
通过配置好的python3命令执行,将会直接打印在终端上。
而python3是一个解释器,它是一边翻译一边执行。
(2)编译形语言,比如c
创建一个c文件,demo.c
#include <stdio.h>
int main(int a,char*argv[]) {
printf("hello\n");
return 0;
}
然后通过clang编译:
clang demo.c
会生成一个a.out文件,通过file命令查看此文件:
file a.out
a.out: Mach-O 64-bit executable x86_64
它是一个Mach-O格式,cpu架构是x86_64的可执行文件。
a.out 就是0101的组合,其中一种是数据,一种是指令。
以上说白了就是,通过编译器将高级语言的代码转化成CPU能看得懂的01组合(机器语言)。
4、汇编语言的特点
最早期的代码都是01组合。后来为了方便编写,会将不同排列的01组合标记为一个指令。举个例子:比如“00001111代表call指令”。随着指令越来越多,像call、mov、bl这种标记就演变成了最早的汇编。
由于早期的计算机生产厂商特别多,cpu的种类也都不一样,也就对01组合的解读也不一样,所以汇编是不跨平台的。
后来随着c语言等高级语言的出现,才实现了跨平台。
三、LLVM的设计
1、传统编译器的设计

-
(1)编译器前端(Frontend)
编译器前端的任务是解析源代码:
<1> 词法分析
<2>语法分析、语义分析
<3>检查源代码是否存在错误
<4>生成抽象语法树(Abstract Syntax Tree,AST) -
(2)优化器(Optimizer)
优化器负责进行各种优化。
<1> 改善代码的运行时间
<2>消除冗余计算等。
比如我们通常使用的高级语言确实是让编程的效率提高了,但是生成了很多没有必要的中间代码。
例如每当我们调用一个函数FuncA时,第一步要找到FuncA的实现代码(内存的寻址跳转)。第二步要开辟内存空间(函数调用栈)压栈,给空间输入值,执行相应代码。最后函数FuncA出栈,再跳转回到调用FuncA的地方继续往下执行。
所以这一系列的过程,如果不做优化的话,会造成时间和空间上的浪费。
- (3)后端(Backend)/ 代码生成器(CodeGenerator)
将代码映射到目标指令集。生成机器语言,并且进行机器相关的代码优化。
2、LLVM的设计
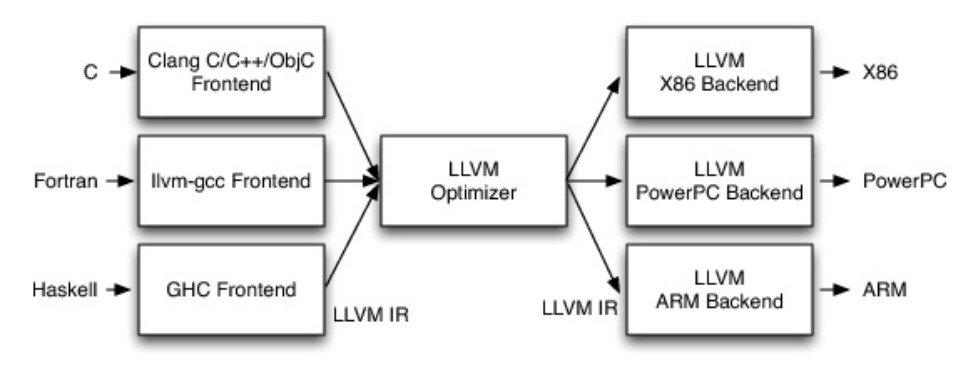
补充:如果是Swift,那么编译器前端是Swift。
当编译器决定支持多种源语言或者多种硬件架构时。传统编译器比如GCC,它们非常成功,但由于它是作为整体应用程序设计的。因此它们的用途受到了很大的限制。
那么LLVM最重要的地方就来了。LLVM设计的最重要方面是,使用通用的代码表示形式(IR),IR是用来在编译器中表示代码的形式。所以LLVM可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端。
- (1)编译器前端(Frontend),会多一个步骤,生成中间代码(intermediate representation,IR)
- (2)优化器(Optimizer),会接收IR,优化完之后,同样的输出IR给后端。
- (3)后端(Backend)/ 代码生成器(CodeGenerator)接收IR,最终生成机器语言。
总结:LLVM(Low Level Virtual Machine,底层虚拟机)通过中间代码IR,实现前后端分离。可以作为多种编译器的后台来使用。
3、IOS的编译器架构
Objective C/C/C++ 使用的编译器前端是Clang,Swift是Swift,后端都是LLVM。
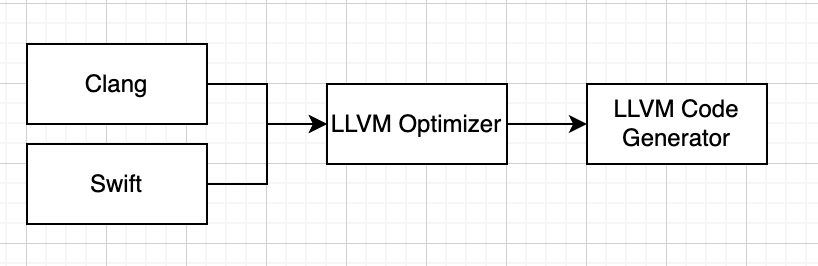
4、Clang
Clang是LLVM项目中的一个子项目。它是基于LLVM架构的轻量级编译器,诞生之初是为了替代GCC,提供更快的编译速度。它是负责编译C、C++、OC的编译器。它属于整个LLVM架构中的编译器前端。对于开发者来说,研究Clang可以给我们带来很多好处。
LLVM从1.0到2.5使用的都是GCC作为前端,直到2.6开始才提供了Clang前端。
四、编译流程
输入以下命令:
clang -ccc-print-phases main.m
编译流程如下:
- 0: input, "main.m", objective-c (输入文件:找到源文件。)
- 1: preprocessor, {0}, objective-c-cpp-output (预处理阶段:这个过程处理包括宏的替换,头文件的导入。)
- 2: compiler, {1}, ir (编译阶段:进行词法分析、语法分析、检测语法是否正确,最终生成IR。)
- 3: backend, {2}, assembler (后端:这里LLVM会通过一个一个的Pass去优化,每个Pass做一些事情,最终生成汇编代码。)
4: assembler, {3}, object (生成目标文件)
5: linker, {4}, image (静态链接:链接需要的动态库和静态库,生成可执行文件。)
6: bind-arch, "x86_64", {5}, image (通过不同的架构、生成对应的可执行文件。)
具体的来看每一个阶段:
1、输入文件,这个很简单,就是找到要编译的源文件。
2、预处理阶段
demo如下:
#import <stdio.h>
#define C 30
int main(int argc, char * argv[]) {
int a = 10;
int b = 20;
printf("%d,%d,%d",a,b,C);
return 0;
}
通过命令:
clang -E main.m >> main2.m
将编译后的结果输出到main2.m文件中。
打开main2.m文件,会发现代码量很大。主要原因是预处理时,会把stdio.h的内容全部copy进来。
再比如当我们加入#import <UIKit/UIKit.h>
xcrun -sdk iphonesimulator clang -E main.m >> main3.m
此时查看main3.m,同样的会把UIKit.h的内容全部copy进来。
再看 #define C,已经被替换成了30。
int main(int argc, char * argv[]) {
int a = 10;
int b = 20;
printf("%d,%d,%d",a,b,30);
return 0;
}
所以宏定义会在预处理阶段进行替换处理。
注意:如果再加入一个typedef int TEST_INT 呢
#import <stdio.h>
#import <UIKit/UIKit.h>
typedef int TEST_INT;
#define C 30
int main(int argc, char * argv[]) {
TEST_INT a = 10;
TEST_INT b = 20;
printf("%d,%d,%d",a,b,C);
return 0;
}
编译之后:
typedef int TEST_INT;
int main(int argc, char * argv[]) {
TEST_INT a = 10;
TEST_INT b = 20;
printf("%d,%d,%d",a,b,30);
return 0;
}
TEST_INT 并没有被替换。
总结:预处理阶段,会将头文件和宏定义进行处理,但是不会对typedef进行处理。
3、编译阶段
继续以以下demo为例:
#import <stdio.h>
typedef int TEST_INT;
#define C 30
int main(int argc, char * argv[]) {
TEST_INT a = 10;
TEST_INT b = 20;
printf("%d,%d,%d",a,b,C);
return 0;
}
(1)词法分析
预处理完成后会进行词法分析,这里会把代码切成一个个Token,比如大小括号,等于号还有字符串等。
通过以下命令进行词法分析:
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m
annot_module_include '#import <stdio.h>
typedef int TEST_INT;
#define C 30
int main(int argc, char * argv[]) {
' Loc=<main.m:8:1>
typedef 'typedef' [StartOfLine] Loc=<main.m:10:1>
int 'int' [LeadingSpace] Loc=<main.m:10:9>
identifier 'TEST_INT' [LeadingSpace] Loc=<main.m:10:13>
semi ';' Loc=<main.m:10:21>
int 'int' [StartOfLine] Loc=<main.m:13:1>
identifier 'main' [LeadingSpace] Loc=<main.m:13:5>
l_paren '(' Loc=<main.m:13:9>
int 'int' Loc=<main.m:13:10>
identifier 'argc' [LeadingSpace] Loc=<main.m:13:14>
comma ',' Loc=<main.m:13:18>
char 'char' [LeadingSpace] Loc=<main.m:13:20>
star '*' [LeadingSpace] Loc=<main.m:13:25>
identifier 'argv' [LeadingSpace] Loc=<main.m:13:27>
l_square '[' Loc=<main.m:13:31>
r_square ']' Loc=<main.m:13:32>
r_paren ')' Loc=<main.m:13:33>
l_brace '{' [LeadingSpace] Loc=<main.m:13:35>
identifier 'TEST_INT' [StartOfLine] [LeadingSpace] Loc=<main.m:15:5>
identifier 'a' [LeadingSpace] Loc=<main.m:15:14>
equal '=' [LeadingSpace] Loc=<main.m:15:16>
numeric_constant '10' [LeadingSpace] Loc=<main.m:15:18>
semi ';' Loc=<main.m:15:20>
identifier 'TEST_INT' [StartOfLine] [LeadingSpace] Loc=<main.m:16:5>
identifier 'b' [LeadingSpace] Loc=<main.m:16:14>
equal '=' [LeadingSpace] Loc=<main.m:16:16>
numeric_constant '20' [LeadingSpace] Loc=<main.m:16:18>
semi ';' Loc=<main.m:16:20>
identifier 'printf' [StartOfLine] [LeadingSpace] Loc=<main.m:17:5>
l_paren '(' Loc=<main.m:17:11>
string_literal '"%d,%d,%d"' Loc=<main.m:17:12>
comma ',' Loc=<main.m:17:22>
identifier 'a' Loc=<main.m:17:23>
comma ',' Loc=<main.m:17:24>
identifier 'b' Loc=<main.m:17:25>
comma ',' Loc=<main.m:17:26>
numeric_constant '30' Loc=<main.m:17:27 <Spelling=main.m:11:11>>
r_paren ')' Loc=<main.m:17:28>
semi ';' Loc=<main.m:17:29>
return 'return' [StartOfLine] [LeadingSpace] Loc=<main.m:19:5>
numeric_constant '0' [LeadingSpace] Loc=<main.m:19:12>
semi ';' Loc=<main.m:19:13>
r_brace '}' [StartOfLine] Loc=<main.m:20:1>
eof '' Loc=<main.m:20:2>
可以看到,词法分析就是将单词、标点等关键词一个一个拆分。并且会记录位置,比如Loc=main.m:10:1,main.m文件中,第10行的第一个位置,就是typedef的开始位置。
(2)语法分析
词法分析完成之后就是语法分析,它的任务是验证语法是否正确。
在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等等,然后将所有节点组成抽象语法树(Abstract Syntax Tree,AST)。
语法分析程序判断源程序在结构上是否正确。
通过以下命令进行语法分析,生成抽象语法树:
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
如果sdk路径找不到,可以指定SDK
clang -isysroot /Applications/Xcode.app/......sdk -fmodules -fsyntax-only -Xclang -ast-dump main.m
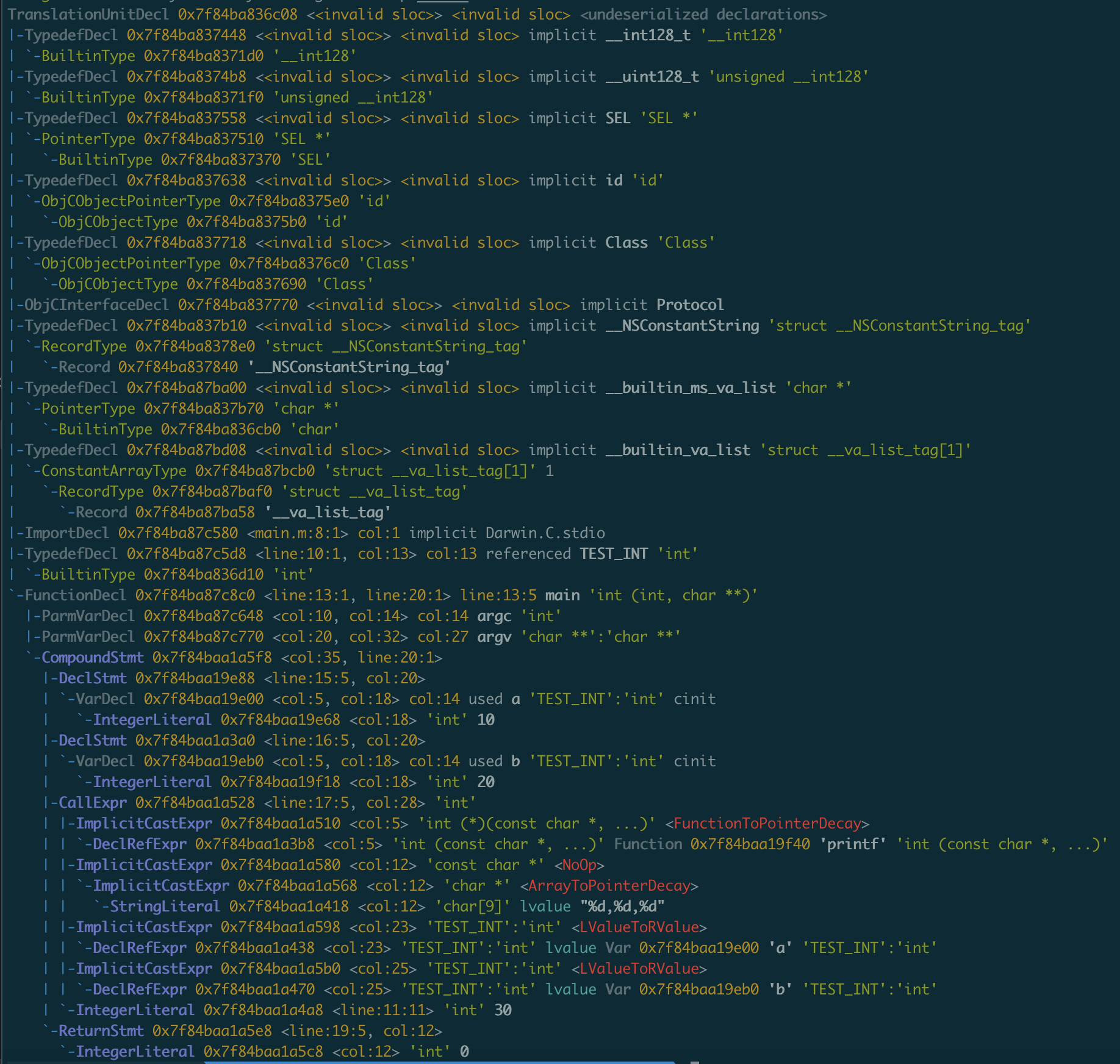
大概说明:
TranslationUnitDecl 顶层节点。
TypedefDecl 对应typedef
BuiltinType 编译原类型
PointerType 对应指针类型
FunctionDecl 对应函数体
ParmVarDecl 对应参数
CompoundStmt 集合节点
该节点代表:代表了像{ stmt stmt } 这样的statement的集合。实际上就是用'{}' and '{{}}' 包裹的代码块。
例如:函数{} 或者 for循环 for (;;) {{}} 这些形式的代码中,的{} 或者 {{}}。
其内部会包含很多子节点。
CallExpr 指调用函数。
那么当我们去掉printf后面的分号时,进行生成ast:
main.m:17:29: error: expected ';' after expression
printf("%d,%d,%d",a,b,C)
^
;
此时就会报错了。
(3)生成中间代码IR(intermediate representation)
完成以上步骤后就开始生成中间代码IR了,代码生成器(Code Generation)会将语法树自顶向下遍历,逐步翻译成LLVM IR。
#import <stdio.h>
int test(int a, int b) {
return a+b+3;
}
int main(int argc, char * argv[]) {
int a = test(1,2);
printf("%d",a);
return 0;
}
通过下面命令将上面的demo生成.ll的文本文件:
clang -S -fobjc-arc -emit-llvm main.m
main.ll如下:
; ModuleID = 'main.m'
source_filename = "main.m"
target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx12.0.0"
@.str = private unnamed_addr constant [3 x i8] c"%d\00", align 1
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @test(i32 %0, i32 %1) #0 {
%3 = alloca i32, align 4 //开辟空间
%4 = alloca i32, align 4 //开辟空间
store i32 %0, i32* %3, align 4 //把%0存到%3中
store i32 %1, i32* %4, align 4 //把%1存到%4中
%5 = load i32, i32* %3, align 4 //把%3取出到%5 相当于:int a5 = a3
%6 = load i32, i32* %4, align 4 //把%4取出到%6 相当于:int b6 = b4
%7 = add nsw i32 %5, %6 //把%5和%6相加,%7 = %5+%6
%8 = add nsw i32 %7, 3 //%8 = %7 + 3
ret i32 %8 //最后return %8
}
; Function Attrs: noinline optnone ssp uwtable
//全局函数main
define i32 @main(i32 %0, i8** %1) #1 {
//%代码局部变量
%3 = alloca i32, align 4 //4字节
%4 = alloca i32, align 4 //4字节
%5 = alloca i8**, align 8 //指针8字节
%6 = alloca i32, align 4 //4字节
store i32 0, i32* %3, align 4
store i32 %0, i32* %4, align 4
store i8** %1, i8*** %5, align 8
//call调用test
%7 = call i32 @test(i32 1, i32 2)
//%7写入到%6
store i32 %7, i32* %6, align 4
//从%6取出到%8
%8 = load i32, i32* %6, align 4
//call调用printf
%9 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str, i64 0, i64 0), i32 %8)
ret i32 0
}
declare i32 @printf(i8*, ...) #2
attributes #0 = { noinline nounwind optnone ssp uwtable "darwin-stkchk-strong-link" "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #1 = { noinline optnone ssp uwtable "darwin-stkchk-strong-link" "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #2 = { "darwin-stkchk-strong-link" "frame-pointer"="all" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10}
!llvm.ident = !{!11}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 12, i32 3]}
!1 = !{i32 1, !"Objective-C Version", i32 2}
!2 = !{i32 1, !"Objective-C Image Info Version", i32 0}
!3 = !{i32 1, !"Objective-C Image Info Section", !"__DATA,__objc_imageinfo,regular,no_dead_strip"}
!4 = !{i32 1, !"Objective-C Garbage Collection", i8 0}
!5 = !{i32 1, !"Objective-C Class Properties", i32 64}
!6 = !{i32 1, !"Objective-C Enforce ClassRO Pointer Signing", i8 0}
!7 = !{i32 1, !"wchar_size", i32 4}
!8 = !{i32 7, !"PIC Level", i32 2}
!9 = !{i32 7, !"uwtable", i32 1}
!10 = !{i32 7, !"frame-pointer", i32 2}
!11 = !{!"Apple clang version 14.0.0 (clang-1400.0.29.102)"}
IR的基本语法
@ 全局标识
% 局部标识
alloca 开辟空间
align 内存对齐
i32 32个bit,4个字节
store 写入内存
load 读取数据
call 调用函数
ret 返回
4、优化器和后端生成汇编
(1)IR的优化:

在Xcode设置中,也可以设置优化等级。Debug中基本不优化,Release中又快又小。
一般来说,LLVM的优化级别分别是 -O0 -O1 -O2 -O3 -Os (第一个是大写英文字母O)。
用以下命令优化IR代码:
clang -Os -S -fobjc-arc -emit-llvm main.m -o main2.ll
main2.ll如下:
; ModuleID = 'main.m'
source_filename = "main.m"
target datalayout = "e-m:o-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx12.0.0"
@.str = private unnamed_addr constant [3 x i8] c"%d\00", align 1
; Function Attrs: mustprogress nofree norecurse nosync nounwind optsize readnone ssp uwtable willreturn
define i32 @test(i32 %0, i32 %1) local_unnamed_addr #0 {
%3 = add i32 %0, 3
%4 = add i32 %3, %1
ret i32 %4
}
; Function Attrs: nofree nounwind optsize ssp uwtable
define i32 @main(i32 %0, i8** nocapture readnone %1) local_unnamed_addr #1 {
%3 = tail call i32 (i8*, ...) @printf(i8* nonnull dereferenceable(1) getelementptr inbounds ([3 x i8], [3 x i8]* @.str, i64 0, i64 0), i32 6) #3, !clang.arc.no_objc_arc_exceptions !12
ret i32 0
}
; Function Attrs: nofree nounwind optsize
declare noundef i32 @printf(i8* nocapture noundef readonly, ...) local_unnamed_addr #2
attributes #0 = { mustprogress nofree norecurse nosync nounwind optsize readnone ssp uwtable willreturn "darwin-stkchk-strong-link" "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #1 = { nofree nounwind optsize ssp uwtable "darwin-stkchk-strong-link" "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #2 = { nofree nounwind optsize "darwin-stkchk-strong-link" "frame-pointer"="all" "no-trapping-math"="true" "probe-stack"="___chkstk_darwin" "stack-protector-buffer-size"="8" "target-cpu"="penryn" "target-features"="+cx16,+cx8,+fxsr,+mmx,+sahf,+sse,+sse2,+sse3,+sse4.1,+ssse3,+x87" "tune-cpu"="generic" }
attributes #3 = { optsize }
!llvm.module.flags = !{!0, !1, !2, !3, !4, !5, !6, !7, !8, !9, !10}
!llvm.ident = !{!11}
!0 = !{i32 2, !"SDK Version", [2 x i32] [i32 12, i32 3]}
!1 = !{i32 1, !"Objective-C Version", i32 2}
!2 = !{i32 1, !"Objective-C Image Info Version", i32 0}
!3 = !{i32 1, !"Objective-C Image Info Section", !"__DATA,__objc_imageinfo,regular,no_dead_strip"}
!4 = !{i32 1, !"Objective-C Garbage Collection", i8 0}
!5 = !{i32 1, !"Objective-C Class Properties", i32 64}
!6 = !{i32 1, !"Objective-C Enforce ClassRO Pointer Signing", i8 0}
!7 = !{i32 1, !"wchar_size", i32 4}
!8 = !{i32 7, !"PIC Level", i32 2}
!9 = !{i32 7, !"uwtable", i32 1}
!10 = !{i32 7, !"frame-pointer", i32 2}
!11 = !{!"Apple clang version 14.0.0 (clang-1400.0.29.102)"}
!12 = !{}
会发现减少了大量的代码。这就是优化器的作用。
另外:Xcode7以后开启bitcode,苹果会做进一步的优化。生成.bc的中间代码。我们可以用以下命令,通过优化后的IR代码生成.bc代码
clang -emit-llvm -c main2.ll -o main.bc
(2)生成汇编文件
这里用源文件、.ll文件、.bc文件分别生成汇编。
(1)源文件
clang -Os -S -fobjc-arc main.m -o main1.s
(2).ll文件
clang -S -fobjc-arc main2.ll -o main2.s
(3).bc文件
clang -S -fobjc-arc main.bc -o main3.s
总结:以上生成汇编之前,都经过了优化,生成的汇编基本没有区别。因为优化器是独立的,全局就一个优化器。
5、生成目标文件(汇编器)
目标文件的生成,是汇编器以汇编代码作为输入,将汇编代码转换为机器代码,最后输出目标文件(object file)。
clang -fmodules -c main1.s -o main.o
通过nm命令,查看生成的main.o中的符号:
xcrun nm -nm main.o
符号如下:
(undefined) external _printf
0000000000000000 (__TEXT,__text) external _test
000000000000000c (__TEXT,__text) external _main
_printf是一个undefined external的。(外部符号)
undefined表示在当前文件暂时找不到符号_printf
external表示这个符号是外部可以访问的
那么printf之所以找不到,是因为它在其他的库中,所以我们还要静态链接。
6、生成可执行文件(链接)
链接器把编译产生的.o文件和(.dylib 、.a)文件,生成一个mach-o文件。
clang main.o -o main
查看链接之后的符号:
xcrun nm -nm main
(undefined) external _printf (from libSystem)
(undefined) external dyld_stub_binder (from libSystem)
0000000100000000 (__TEXT,__text) [referenced dynamically] external __mh_execute_header
0000000100003f6b (__TEXT,__text) external _test
0000000100003f77 (__TEXT,__text) external _main
0000000100008008 (__DATA,__data) non-external __dyld_private
可以看到_printf来自libSystem。
另外main的可执行文件默认是x86_64的。如果要生成其他的架构,可以设置clang的-arch参数。
以上就是编译器编译的整体流程。