OC底层 - 方法缓存(cache_t)
前言
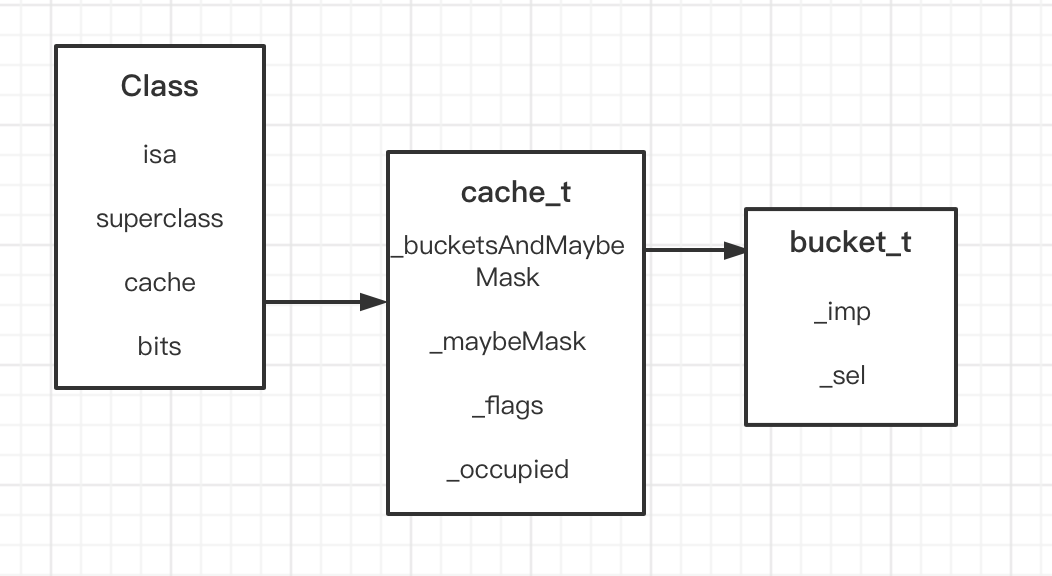
一、cache_t 的结构
二、cache_t 分析
三、cache_t 数据结构 - 哈希表(散列表)
四、cache_t 的数据存储
五、cache_t 缓存流程图
对OC的“类”有了基本认知之后,继续来分析一下类的缓存思想 - cache_t。分析之前同样的抛出几个问题:
1、cache_t的结构是怎样的?
2、缓存的执行流程是怎样的?
一、cache_t 的结构
1、由于818.2版本的cache_t看起来东西比较多,这里针对性的去筛检一些代码。
首先看下内部定义的宏
#if defined(__arm64__) && __LP64__
#if TARGET_OS_OSX || TARGET_OS_SIMULATOR
/// os模拟器
#define CACHE_MASK_STORAGE CACHE_MASK_STORAGE_HIGH_16_BIG_ADDRS
#else
/// 真机
#define CACHE_MASK_STORAGE CACHE_MASK_STORAGE_HIGH_16
#endif
#elif defined(__arm64__) && !__LP64__
///64位以下
#define CACHE_MASK_STORAGE CACHE_MASK_STORAGE_LOW_4
#else
///x86_64
#define CACHE_MASK_STORAGE CACHE_MASK_STORAGE_OUTLINED
#endif
对宏进行了区分:
1、只需要判断 CACHE_MASK_STORAGE_OUTLINED 和 CACHE_MASK_STORAGE_HIGH_16
两种情况即可,也就是广义上来说就是真机环境和非真机环境。
2、CONFIG_USE_PREOPT_CACHES 这个宏的意思是,是否支持预优化缓存,这里我们先不考虑,有关CONFIG_USE_PREOPT_CACHES这个的判断直接先省略。
整理代码:
struct cache_t {
private:
explicit_atomic<uintptr_t> _bucketsAndMaybeMask; //8
union {
struct {
explicit_atomic<mask_t> _maybeMask; //4
uint16_t _flags; //2
uint16_t _occupied; //2
};
explicit_atomic<preopt_cache_t *> _originalPreoptCache;
};
#if CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_OUTLINED
// _bucketsAndMaybeMask is a buckets_t pointer
// _maybeMask is the buckets mask
static constexpr uintptr_t bucketsMask = ~0ul;
static_assert(!CONFIG_USE_PREOPT_CACHES, "preoptimized caches not supported");
#elif CACHE_MASK_STORAGE == CACHE_MASK_STORAGE_HIGH_16
// _bucketsAndMaybeMask is a buckets_t pointer in the low 48 bits
// _maybeMask is unused, the mask is stored in the top 16 bits.
// How much the mask is shifted by.
static constexpr uintptr_t maskShift = 48;
// Additional bits after the mask which must be zero. msgSend
// takes advantage of these additional bits to construct the value
// `mask << 4` from `_maskAndBuckets` in a single instruction.
static constexpr uintptr_t maskZeroBits = 4;
// The largest mask value we can store.
static constexpr uintptr_t maxMask = ((uintptr_t)1 << (64 - maskShift)) - 1;
// The mask applied to `_maskAndBuckets` to retrieve the buckets pointer.
static constexpr uintptr_t bucketsMask = ((uintptr_t)1 << (maskShift - maskZeroBits)) - 1;
// Ensure we have enough bits for the buckets pointer.
static_assert(bucketsMask >= MACH_VM_MAX_ADDRESS,
"Bucket field doesn't have enough bits for arbitrary pointers.");
#endif
bool isConstantEmptyCache() const;
bool canBeFreed() const;
mask_t mask() const;
void incrementOccupied();
void setBucketsAndMask(struct bucket_t *newBuckets, mask_t newMask);
void reallocate(mask_t oldCapacity, mask_t newCapacity, bool freeOld);
void collect_free(bucket_t *oldBuckets, mask_t oldCapacity);
static bucket_t *emptyBuckets();
static bucket_t *allocateBuckets(mask_t newCapacity);
static bucket_t *emptyBucketsForCapacity(mask_t capacity, bool allocate = true);
static struct bucket_t * endMarker(struct bucket_t *b, uint32_t cap);
void bad_cache(id receiver, SEL sel) __attribute__((noreturn, cold));
public:
// The following four fields are public for objcdt's use only.
// objcdt reaches into fields while the process is suspended
// hence doesn't care for locks and pesky little details like this
// and can safely use these.
unsigned capacity() const;
struct bucket_t *buckets() const;
Class cls() const;
mask_t occupied() const;
void initializeToEmpty();
inline bool isConstantOptimizedCache(bool strict = false, uintptr_t empty_addr = 0) const { return false; }
inline bool shouldFlush(SEL sel, IMP imp) const {
return cache_getImp(cls(), sel) == imp;
}
inline bool isConstantOptimizedCacheWithInlinedSels() const { return false; }
inline void initializeToEmptyOrPreoptimizedInDisguise() { initializeToEmpty(); }
void insert(SEL sel, IMP imp, id receiver);
void copyCacheNolock(objc_imp_cache_entry *buffer, int len);
void destroy();
void eraseNolock(const char *func);
static void init();
static void collectNolock(bool collectALot);
static size_t bytesForCapacity(uint32_t cap);
bool getBit(uint16_t flags) const {
return _flags & flags;
}
void setBit(uint16_t set) {
__c11_atomic_fetch_or((_Atomic(uint16_t) *)&_flags, set, __ATOMIC_RELAXED);
}
void clearBit(uint16_t clear) {
__c11_atomic_fetch_and((_Atomic(uint16_t) *)&_flags, ~clear, __ATOMIC_RELAXED);
}
bool hasFastInstanceSize(size_t extra) const
{
if (__builtin_constant_p(extra) && extra == 0) {
return _flags & FAST_CACHE_ALLOC_MASK16;
}
return _flags & FAST_CACHE_ALLOC_MASK;
}
size_t fastInstanceSize(size_t extra) const
{
ASSERT(hasFastInstanceSize(extra));
if (__builtin_constant_p(extra) && extra == 0) {
return _flags & FAST_CACHE_ALLOC_MASK16;
} else {
size_t size = _flags & FAST_CACHE_ALLOC_MASK;
// remove the FAST_CACHE_ALLOC_DELTA16 that was added
// by setFastInstanceSize
return align16(size + extra - FAST_CACHE_ALLOC_DELTA16);
}
}
void setFastInstanceSize(size_t newSize)
{
// Set during realization or construction only. No locking needed.
uint16_t newBits = _flags & ~FAST_CACHE_ALLOC_MASK;
uint16_t sizeBits;
// Adding FAST_CACHE_ALLOC_DELTA16 allows for FAST_CACHE_ALLOC_MASK16
// to yield the proper 16byte aligned allocation size with a single mask
sizeBits = word_align(newSize) + FAST_CACHE_ALLOC_DELTA16;
sizeBits &= FAST_CACHE_ALLOC_MASK;
if (newSize <= sizeBits) {
newBits |= sizeBits;
}
_flags = newBits;
}
};
2、通过筛检的代码分析可得,cache_t的核心成员是:
(1)_bucketsAndMaybeMask
(2)联合体
struct cache_t {
private:
explicit_atomic<uintptr_t> _bucketsAndMaybeMask; //8
union {
struct {
explicit_atomic<mask_t> _maybeMask; //4
uint16_t _flags; //2
uint16_t _occupied; //2
};
explicit_atomic<preopt_cache_t *> _originalPreoptCache;
};
二、cache_t 分析
1、首先我们通过第一个属性_bucketsAndMaybeMask知道,bucket是一个桶子,那么cache肯定是对bucket进行增删改查来操作的。
struct bucket_t {
private:
// IMP-first is better for arm64e ptrauth and no worse for arm64.
// SEL-first is better for armv7* and i386 and x86_64.
#if __arm64__
explicit_atomic<uintptr_t> _imp;
explicit_atomic<SEL> _sel;
#else
explicit_atomic<SEL> _sel;
explicit_atomic<uintptr_t> _imp;
#endif
.......
}
通过bucket_t的结构体也就验证了,方法缓存确实保存在了bucket里面。那么bucket是怎么来存储的呢?
那么我们先宏观的来总结一下:
2、通过lldb打印缓存方法,我在MyTestObjc中加入了-(void)test1;和-(void)test2;方法。
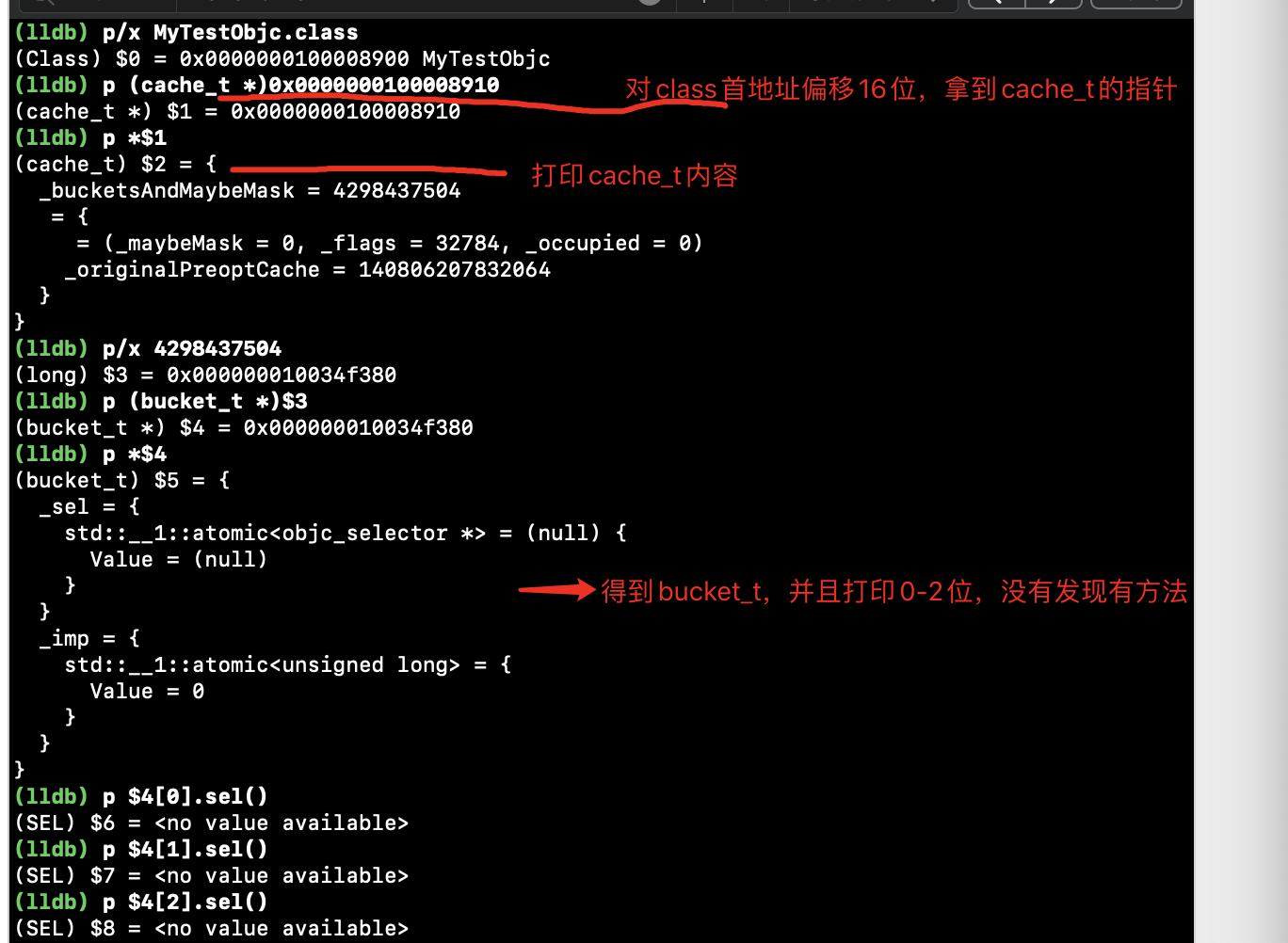
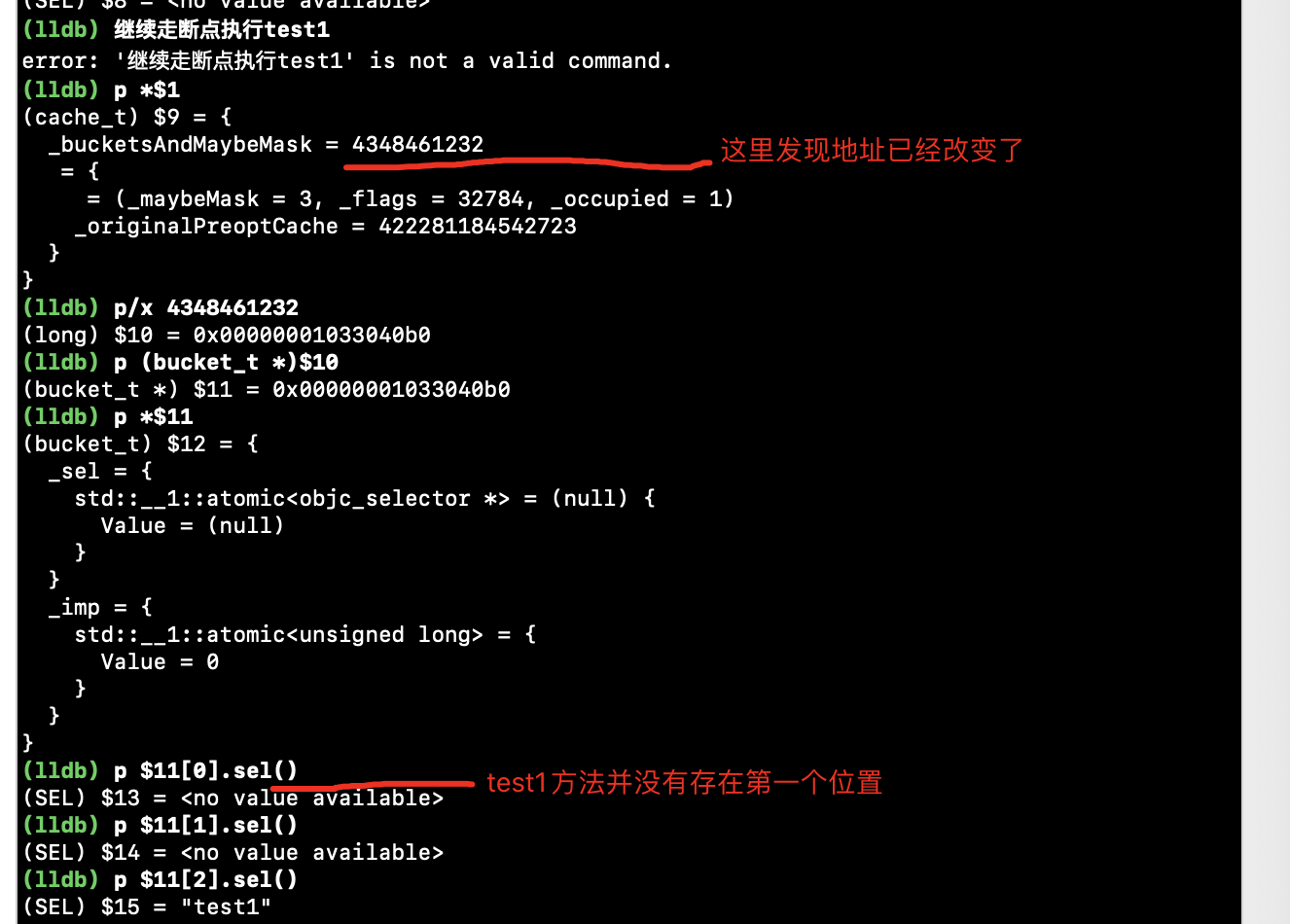
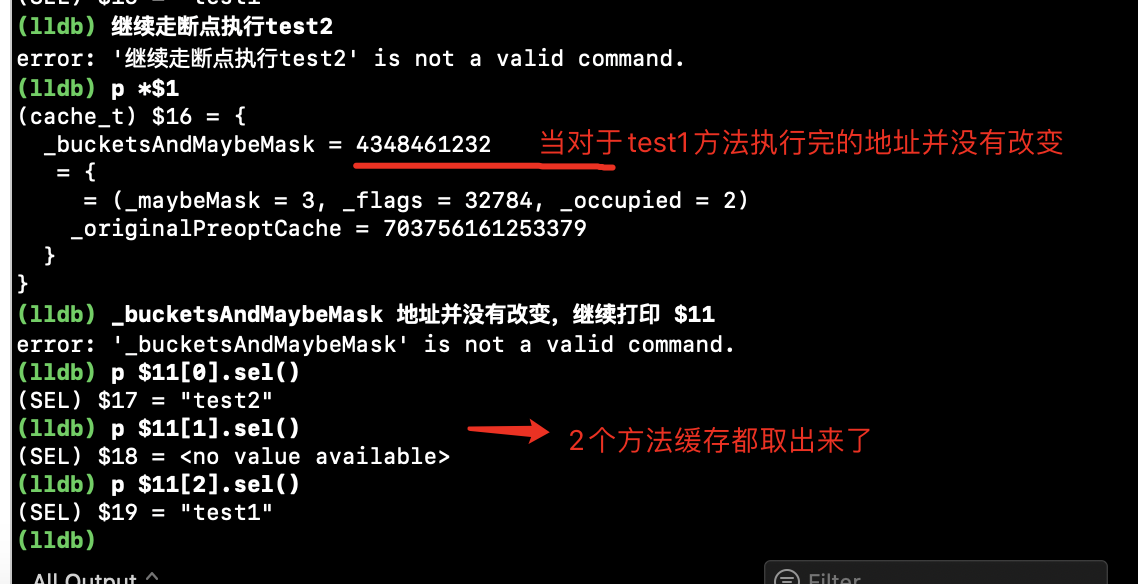
通过lldb,最终打印出了test1和test2方法。
但是有2个现象:
1、在断点没有走到test1的时候,_bucketsAndMaybeMask的地址为:0x000000010034f380。
当执行test1之后,_bucketsAndMaybeMask的地址为:0x00000001033040b0。
2、第一次读到test1缓存方法的时候,为什么没有放在第一个位置。
通过这2个现象,可以断定出,cache_t肯定不是通过一个简单的数组依次去存放方法的。我们再查找方法的时候必须要快速的定位,所以这里肯定是用了哈希表(散列表)。
3、在分析缓存过程之前,尝试脱离源码环境来更方便的调试cache_t。
struct mg_bucket_t {
SEL _sel;
IMP _imp;
};
struct preopt_cache_entry_t {
uint32_t sel_offs;
uint32_t imp_offs;
};
struct preopt_cache_t {
int32_t fallback_class_offset;
union {
struct {
uint16_t shift : 5;
uint16_t mask : 11;
};
uint16_t hash_params;
};
uint16_t occupied : 14;
uint16_t has_inlines : 1;
uint16_t bit_one : 1;
struct preopt_cache_entry_t entries[];
inline int capacity() const {
return mask + 1;
}
};
struct mg_cache_t {
mg_bucket_t *_bucketsAndMaybeMask; //8
union {
struct {
mask_t _maybeMask; //4
#if __LP64__
uint16_t _flags; //2
#endif
uint16_t _occupied; //2
};
preopt_cache_t *_originalPreoptCache;
};
};
struct class_data_bits_t {
uintptr_t bits;
};
struct mg_objc_class {
Class ISA; //8
Class superclass; //8
mg_cache_t cache; //16 // formerly cache pointer and vtable
class_data_bits_t bits; // class_rw_t * plus custom rr/alloc flags
};
int main(int argc, char * argv[]) {
NSString * appDelegateClassName;
@autoreleasepool {
// Setup code that might create autoreleased objects goes here.
appDelegateClassName = NSStringFromClass([AppDelegate class]);
MyTestObjc *objc = [MyTestObjc alloc];
[objc test1];
[objc test2];
Class mClass = [MyTestObjc class];
//将mClass强转为mg_objc_class类型
struct mg_objc_class *mg_class = (__bridge mg_objc_class *) mClass;
NSLog(@"%d - %d",mg_class->cache._occupied,mg_class->cache._maybeMask);
//遍历打印cache中的内容
for (mask_t i = 0; i < mg_class->cache._maybeMask; i++) {
NSLog(@"%@ - %p",NSStringFromSelector(mg_class->cache._bucketsAndMaybeMask[i]._sel),mg_class->cache._bucketsAndMaybeMask[i]._imp);
}
}
return UIApplicationMain(argc, argv, nil, appDelegateClassName);
}
打印结果:
2021-05-04 11:04:38.661662+0800 cache_t_demo[1042:35676] 2 - 3
2021-05-04 11:04:38.661794+0800 cache_t_demo[1042:35676] test2 - 0x19438
2021-05-04 11:04:38.661894+0800 cache_t_demo[1042:35676] (null) - 0x0
2021-05-04 11:04:38.661960+0800 cache_t_demo[1042:35676] test1 - 0x19428
通过自定义的数据结构,将class强转为mg_objc_class,最终打印出了所有的缓存方法。
三、cache_t 数据结构 - 哈希表(散列表)
通过lldb和脱离源代码的形式,以及抛出的问题,我们可以确定,缓存是通过散列表来存储的。
关于哈希表可以看这篇博客:哈希表原理
接下来,我们就具体的分析,cache_t内是如何插入数据,读取数据,以及如何解决散列冲突的。
四、cache_t 的数据存储
对于cache_t是存储的过程,需要针对cache_t中的方法进行分析。
在cache_t中有一个insert方法,就是要插入sel 和 imp的地方。
对insert方法进行筛检,只保留主要逻辑:
///插入sel和imp
void cache_t::insert(SEL sel, IMP imp, id receiver)
{
// Use the cache as-is if until we exceed our expected fill ratio.
//等于原有的occupied +1
mask_t newOccupied = occupied() + 1;
/** 散列表的容量 = mask +1
unsigned cache_t::capacity() const
{
return mask() ? mask()+1 : 0;
}
**/
unsigned oldCapacity = capacity(), capacity = oldCapacity;
if (slowpath(isConstantEmptyCache())) {
// Cache is read-only. Replace it.
if (!capacity) capacity = INIT_CACHE_SIZE; // INIT_CACHE_SIZE = (1 << INIT_CACHE_SIZE_LOG2) = 4
//第一次开辟4个容量的空间
reallocate(oldCapacity, capacity, /* freeOld */false);
}
else if (fastpath(newOccupied + CACHE_END_MARKER <= cache_fill_ratio(capacity))) {
// Cache is less than 3/4 or 7/8 full. Use it as-is.
/** 已缓存的数量 如果 小于等于 总容量的3/4,不做处理
static inline mask_t cache_fill_ratio(mask_t capacity) {
return capacity * 3 / 4;
}
**/
}
else {
//已缓存的数量 如果 大于 总容量的3/4,将总容量扩容至2倍
capacity = capacity ? capacity * 2 : INIT_CACHE_SIZE;
//最大值限制
if (capacity > MAX_CACHE_SIZE) {
capacity = MAX_CACHE_SIZE;
}
//重新开辟内存
reallocate(oldCapacity, capacity, true);
}
bucket_t *b = buckets();
//mask 为总容量 - 1
mask_t m = capacity - 1;
/** 将sel 与 上mask 作为哈希表的下标
static inline mask_t cache_hash(SEL sel, mask_t mask)
{
uintptr_t value = (uintptr_t)sel;
#if CONFIG_USE_PREOPT_CACHES
value ^= value >> 7;
#endif
return (mask_t)(value & mask);
}
**/
mask_t begin = cache_hash(sel, m);
mask_t i = begin;
// Scan for the first unused slot and insert there.
// There is guaranteed to be an empty slot.
///循环遍历判断:1、是否被其他线程已经加入过了 2、是否存在散列冲突
do {
if (fastpath(b[i].sel() == 0)) {
///如果该下标空闲直接插入sel和imp,并且对Occupied+1
incrementOccupied();
/*
void cache_t::incrementOccupied()
{
_occupied++;
}
*/
//插入时通过encodeImp 编码,绑定类的关系
b[i].set<Atomic, Encoded>(b, sel, imp, cls());
return;
}
if (b[i].sel() == sel) {
//被其他线程已经加入过了
// The entry was added to the cache by some other thread
// before we grabbed the cacheUpdateLock.
return;
}
///通过开放寻址法-再次哈希 来解决哈希冲突
} while (fastpath((i = cache_next(i, m)) != begin));
// #elif __arm64__
// static inline mask_t cache_next(mask_t i, mask_t mask) {
// return i ? i-1 : mask;
// }
bad_cache(receiver, (SEL)sel);
}
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity, bool freeOld)
{
bucket_t *oldBuckets = buckets();
//calloc 开辟空间 ((bucket_t *)calloc(bytesForCapacity(newCapacity), 1);)
/**
size_t cache_t::bytesForCapacity(uint32_t cap)
{
// 16字节对齐
return sizeof(bucket_t) * cap;
}
**/
bucket_t *newBuckets = allocateBuckets(newCapacity);
// Cache's old contents are not propagated.
// This is thought to save cache memory at the cost of extra cache fills.
// fixme re-measure this
///重新设置cache_t中的 _bucketsAndMaybeMask地址,mask值 以及初始化_occupied = 0
setBucketsAndMask(newBuckets, newCapacity - 1);
if (freeOld) {
///通过算法释放一定的空间
collect_free(oldBuckets, oldCapacity);
}
}
通过对insert方法的分析,可以解开疑惑:
1、occupied 就是所占用的空间数量,也就是缓存的方法数量。
2、mask就是掩码数据,等于总容量减一。
3、bucket再超过总容量3/4的时候,会进行扩容,扩容的同时会删除旧的一些数据。
4、插入新的数据时,根据sel&mask得到数组下标,进行插入。如果存在冲突,会再次哈希拿下标。
五、cache_t 缓存流程图
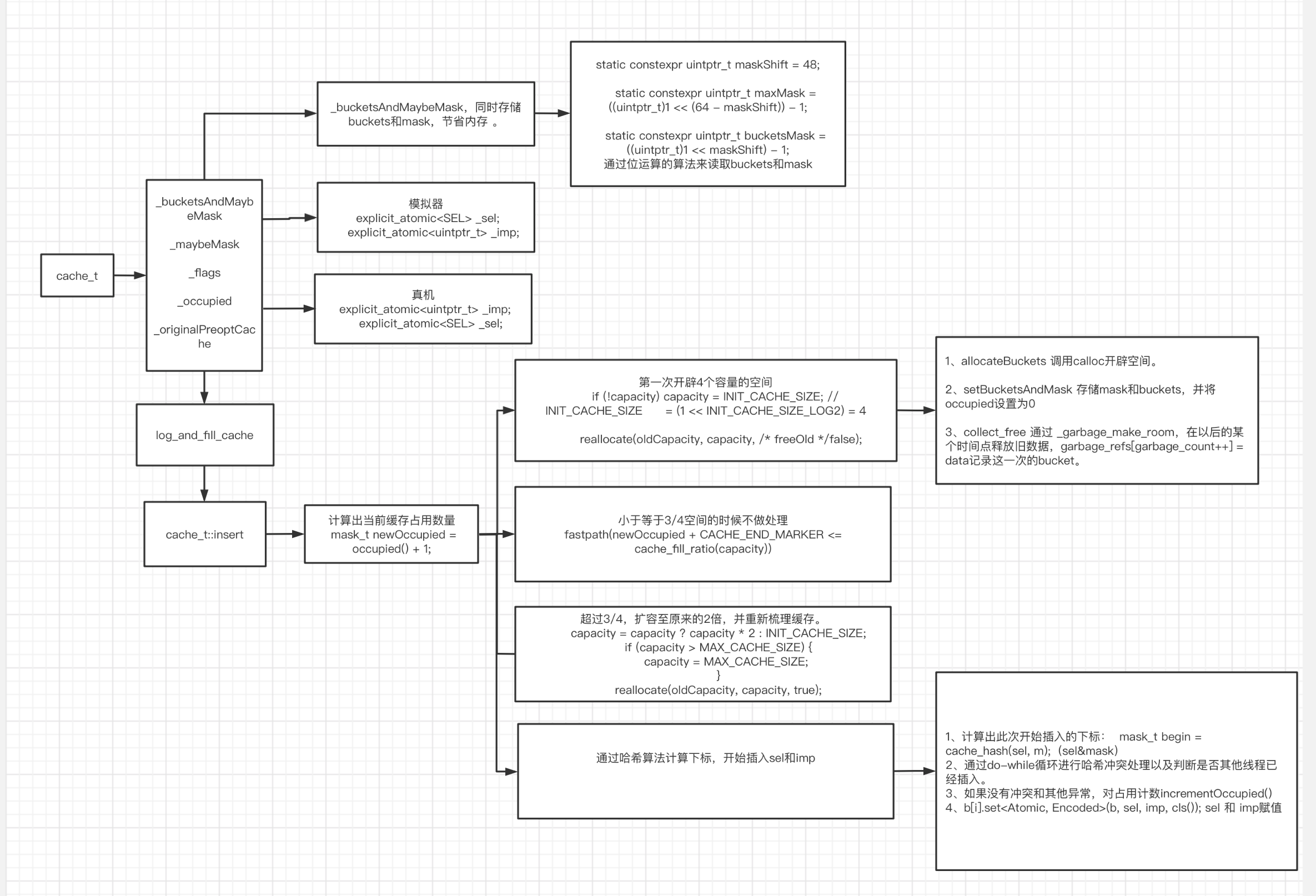
补充1: 如果子类调父类的方法,那么缓存依然会根据当前的类去存储。
补充2 :alloc、load、initialize 方法不会被缓存,因为对这些初始化或者只走一次的方法缓存没有必要性。
补充3: 关于lldb打印的时候,如果是结构体用.来获取成员或者调度方法,如果是结构体指针用->来获取成员或者调度方法
$16 是结构体指针 $17 是结构体
(lldb) p $17._bucketsAndMaybeMask
(explicit_atomic<unsigned long>) $18 = {
std::__1::atomic<unsigned long> = {
Value = 4298437504
}
}
(lldb) p $16->_bucketsAndMaybeMask
(explicit_atomic<unsigned long>) $19 = {
std::__1::atomic<unsigned long> = {
Value = 4298437504
}
}
而OC中的对象的点语法实质是getter方法和setter方法的调用
是编译器的特性,编译器遇到点语法就转换为相应的setter或getter方法。