OC底层 - 消息流程 - cache快速查找流程
前言
一、Runtime
二、objc_msgSend代码初探
三、objc_msgSend汇编实现
四、方法快速查找(cache的查找流程)
通过对cache_t的探索,我们清楚了整个cache_t的结构以及缓存方法的流程。但是缓存方法是在什么时候去进行插入的呢?然后缓存方法又是如何去查找的呢?那么我们就要对整个方法的查找流程进行深入的分析了。
一、Runtime
我们都知道oc方法的底层都是走的消息发送,通过clang编译下面的代码
int main(int argc, const char * argv[]) {
@autoreleasepool {
MyTestObjc *objc = [[MyTestObjc alloc] init];
[objc test1];
}
return 0;
}
编译之后:
MyTestObjc *objc = ((MyTestObjc *(*)(id, SEL))(void *)objc_msgSend)((id)((MyTestObjc *(*)(id, SEL))(void *)objc_msgSend)((id)objc_getClass("MyTestObjc"), sel_registerName("alloc")), sel_registerName("init"));
((void (*)(id, SEL))(void *)objc_msgSend)((id)objc, sel_registerName("test1"));
那么在编译期,每一个方法的调用都会变成objc_msgSend函数。
然后在运行时,通过objc_msgSend去进行消息发送。
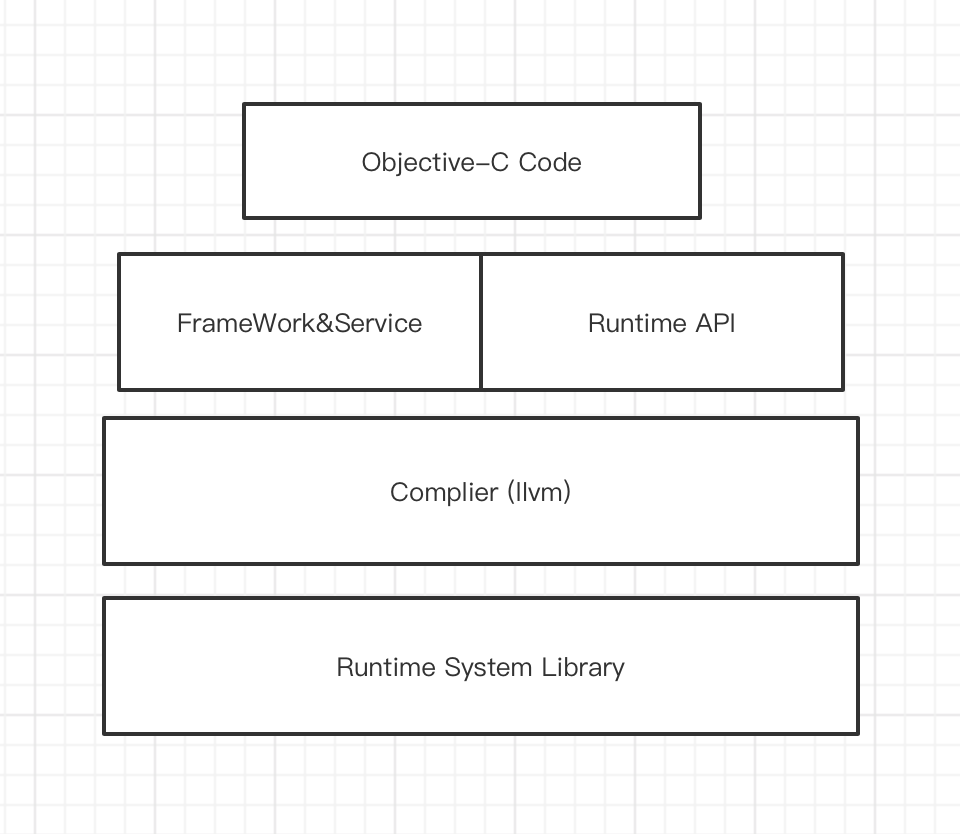
先总结一下Runtime:
从编译时和链接时再到运行时,Objective-C语言会尽可能多地推迟决策。它就会动态地执行操作。这意味着该语言不仅需要编译器,而且还需要运行时系统来执行编译后的代码。运行系统充当一种用于Objective-C语言的操作系统;这就是oc动态性的原因。Runtime 就是一套由c/c++、汇编写的API,使程序在运行时动态的创建对象、检查对象以及修改类和对象的方法等。
我们在调用Runtime的时候,总共有3种途径:
1、通过OC代码直接调用(比如: [objc test1])
2、通过framework/service(比如: iskindOfClass)
3、直接通过Runtime Api (比如:objc_msgSend)。
二、objc_msgSend代码初探
MyTestObjc *objc = [[MyTestObjc alloc] init];
objc_msgSend(objc,@selector(test));
上面代码可以看到,我们可以直接用objc_msgSend函数来发送消息。此时需要在build setting关闭objc_msgSend的检测机制:

我再建一个MyTestObjc的父类(MyBaseTestObjc),在父类里面实现baseTest方法。
MyTestObjc *objc = [[MyTestObjc alloc] init];
objc_msgSend(objc,@selector(baseTest));
同样的可以用objc_msgSend发送消息。
与此同时,也可以直接通过objc_msgSendSuper的方法直接给父类发消息。
OBJC_EXPORT void
objc_msgSendSuper(void /* struct objc_super *super, SEL op, ... */ )
OBJC_AVAILABLE(10.0, 2.0, 9.0, 1.0, 2.0);
通过objc_msgSendSuper的方法定义,我们可以确定其2个参数,第一个是objc_super,第二个sel。
/// Specifies the superclass of an instance.
struct objc_super {
/// Specifies an instance of a class.
__unsafe_unretained _Nonnull id receiver;
/// Specifies the particular superclass of the instance to message.
#if !defined(__cplusplus) && !__OBJC2__ // 不用关系
/* For compatibility with old objc-runtime.h header */
__unsafe_unretained _Nonnull Class class;
#else
__unsafe_unretained _Nonnull Class super_class;
#endif
/* super_class is the first class to search */
};
#endif
继续通过objc_super结构体可以确定,objc_super有2个成员,一个是receiver(消息接受者),一个是super_class(父类)。
所以可以直接由下面代码来进行父类消息发送:
struct objc_super mySupter;
mySupter.receiver = objc;
mySupter.super_class = MyBaseTestObjc.class;
objc_msgSendSuper(&mySupter, @selector(baseTest));
三、objc_msgSend汇编实现
首先看了源码之后,objc_msgSend是用汇编写的。
1、使用汇编的原因首先是快!可以免去大量局部变量拷贝的操作,会更有针对性的去运算,参数会直接被存放在寄存器中,当找到IMP时,参数已经保存在了寄存器中,可以直接使用
2、由于方法的参数有不确定性,我们在用c/c++的时候,无法更好的满足不确定的参数需求。当然c/c++可以使用va_list来实现动态参数,但是从效率上来说还是汇编更高。
四、方法快速查找(cache的查找流程)
ENTRY _objc_msgSend
UNWIND _objc_msgSend, NoFrame
cmp p0, #0 // nil check and tagged pointer check cmp对比命令 po代表对象的isa地址
#if SUPPORT_TAGGED_POINTERS //是否是taggedpointers对象
b.le LNilOrTagged // (MSB tagged pointer looks negative)
#else
b.eq LReturnZero
#endif
//
ldr p13, [x0] // p13 = isa //ldr加载指令,取x0地址的内容保存在p13,p13就是对象的isa
GetClassFromIsa_p16 p13, 1, x0 // p16 = class 通过isa&mask = class
LGetIsaDone: //获取isa完毕
// calls imp or objc_msgSend_uncached
CacheLookup NORMAL, _objc_msgSend, __objc_msgSend_uncached
#if SUPPORT_TAGGED_POINTERS
LNilOrTagged:
b.eq LReturnZero // nil check
GetTaggedClass
b LGetIsaDone
// SUPPORT_TAGGED_POINTERS
#endif
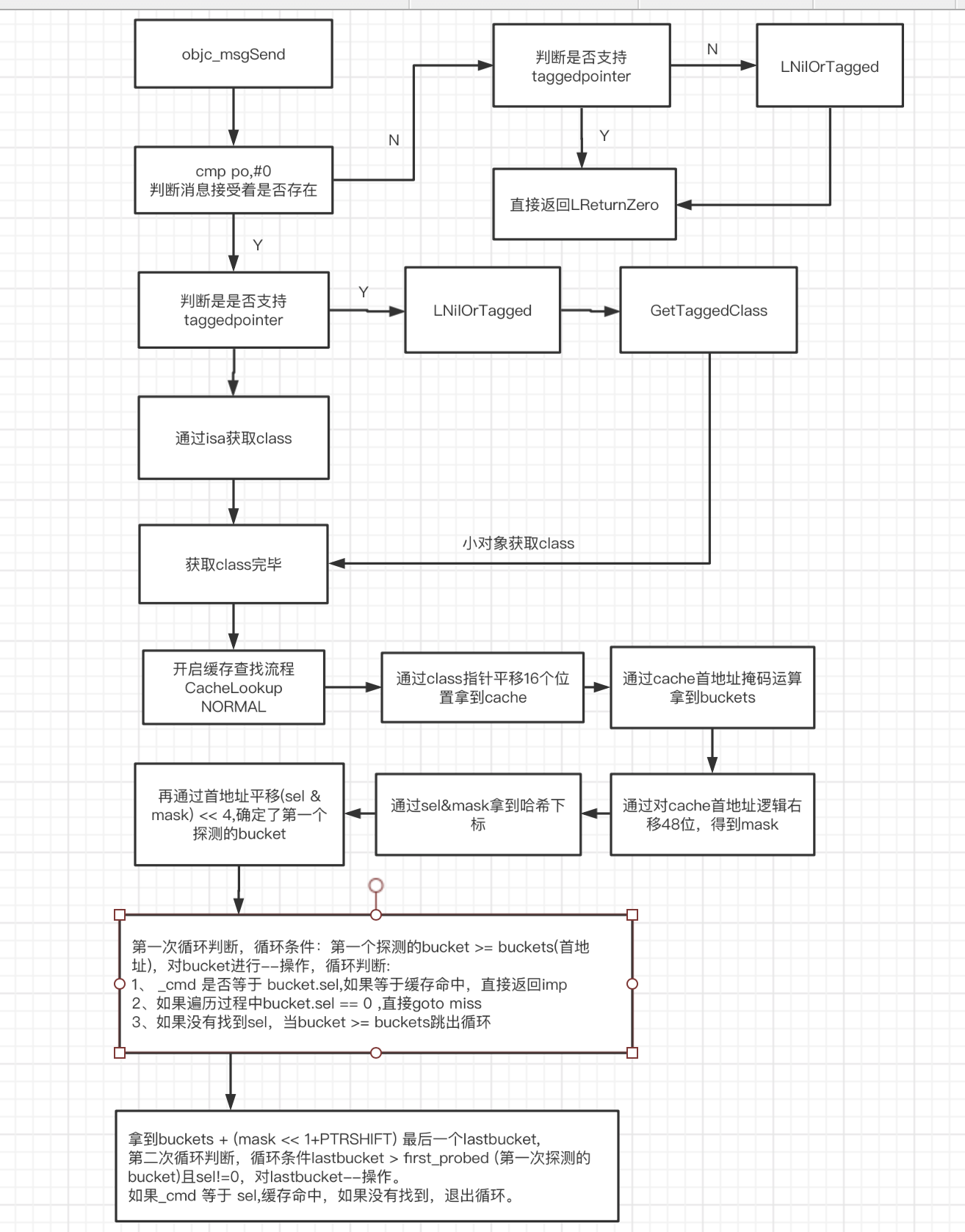
通汇编可以看到,首先拿到消息接受者对象,判断是否为空,如果为空直接返回0,这也是为什么给nil发消息不会崩溃的原因。接着如果不为空,拿到对象的首地址,加载首地址对应的值,也就是isa,放到p13中。然后通过与掩码的&操作,得到class。接着会走CacheLookup流程,也就是缓存查找流程。
以下简化CacheLookup的汇编(不区分宏定义的判断):
.macro CacheLookup Mode, Function, MissLabelDynamic, MissLabelConstant
mov x15, x16 // stash the original isa //mov数据传送指令
LLookupStart\Function:
// p1 = SEL, x16 = isa
ldr p11, [x16, #CACHE] // p11 = mask|buckets //#define CACHE (2 * __SIZEOF_POINTER__) 通过isa的地址,位移16的字节,找到对应的mask|buckets,也就是cache_t中的第一个成员
and p10, p11, #0x0000ffffffffffff // p10 = buckets 通过p10加上掩码,得到buckets
and p12, p1, p11, LSR #48 // p12 = _cmd & mask //首先p11 逻辑右移48位 (存的时候:_bucketsAndMaybeMask.store(((uintptr_t)newMask << maskShift) | (uintptr_t)newBuckets)所以可以直接拿到mask,然后p12 = _cmd & mask 拿到哈希索引。
#error Unsupported cache mask storage for ARM64.
#endif
add p13, p10, p12, LSL #(1+PTRSHIFT)
// p13 = buckets + ((_cmd & mask) << (1+PTRSHIFT)) //PTRSHIFT = 3 ,这句代码意思就是:buckets为首地址,因为一个bucket是16个字节,所以 通过 (_cmd & mask) << (1+PTRSHIFT),就平移到了指定的bucket的了。
// do {
1: ldp p17, p9, [x13], #-BUCKET_SIZE // {imp, sel} = *bucket--
cmp p9, p1 // if (sel != _cmd) {
b.ne 3f // scan more
// } else {
2: CacheHit \Mode // hit: call or return imp
// }
3: cbz p9, \MissLabelDynamic // if (sel == 0) goto Miss;
cmp p13, p10 // } while (bucket >= buckets) //
b.hs 1b
add p13, p10, p11, LSR #(48 - (1+PTRSHIFT))
// p13 = buckets + (mask << 1+PTRSHIFT)
// see comment about maskZeroBits
add p12, p10, p12, LSL #(1+PTRSHIFT)
// p12 = first probed bucket
// do {
4: ldp p17, p9, [x13], #-BUCKET_SIZE // {imp, sel} = *bucket--
cmp p9, p1 // if (sel == _cmd)
b.eq 2b // goto hit
cmp p9, #0 // } while (sel != 0 &&
ccmp p13, p12, #0, ne // bucket > first_probed)
b.hi 4b
1、首先通过isa位移16个字节拿到cache_t,cache_t的首地址也就是指向_buketsAndMaybeMask。
2、接着通过_buketsAndMaybeMask & 0x0000ffffffffffff 得到buckets。
3、再通过_buketsAndMaybeMask右移48位拿到mask,然后通过sel & mask 拿到哈希索引。
4、再通过首地址平移(sel & mask) << 4(因为一个bucket是16个字节,所以通过 (_cmd & mask) << (1+PTRSHIFT),就平移到了指定的bucket的了), 确定了bucket。
5、判断bucket里面的sel 是否等于要查找的sel,如果等于直接返回imp。
6、如果不等于,开始向前遍历查找。查找时,如果sel ==0 直接goto miss
7、如果循环下来还没有找到,将从最后一个桶子继续循环向前查找,直到遍历到第一次确定的桶子时还没有找到,查找结束,goto miss。
流程图总结:
补充:为什么CacheLookup拿到第一次探测的bucket后要向前查找,这里我的分析是:在insert插入缓存的时候,为了解决哈希冲突,使用了再次哈希取下标
#elif __arm64__
static inline mask_t cache_next(mask_t i, mask_t mask) {
return i ? i-1 : mask;
}
而再次哈希的算法是: 对原来的下标进行-1的操作,也是一个向前插入的过程。所以cache的查找和插入流程就完美的契合了。